
Making use of Days Since Last Run
By Henry Young on Thursday, March 31st, 2022I have learned the hard way that a quick turnaround is a red flag for laying. Trainers will sometimes run a horse again only a few days after a much improved run or a win. They do this to capitalize on a horse coming into form, especially in handicaps to beat the handicapper reassessment delay. But how can we quantify the impact of this phenomenon, whether for use in a custom racecard analysis or for feeding into a machine learning (ML) system.
Smartform contains a field “days_since_ran” in both daily_runners and historic_runners tables. However, seeing that a runner last ran x days ago does not really tell you much other than a little of what’s in the trainer’s mind. And this data point is completely unsuitable for passing on to ML because it is not normalized. The easiest solution is to convert it into a Strike Rate percentage:
Strike Rate = Number of wins / Number of races
We need to count races, count wins and calculate Strike Rate percentages. This can be done in SQL as follows:
SELECT
sub.days_since_ran,
sub.race_count,
sub.win_count,
round(sub.win_count / sub.race_count * 100, 1) AS strike_rate
FROM (
SELECT
days_since_ran,
COUNT(*) as race_count,
COUNT(IF(finish_position = 1, 1, NULL)) AS win_count
FROM
historic_runners_beta
JOIN
historic_races_beta
USING(race_id)
WHERE
days_since_ran IS NOT NULL AND
year(meeting_date) >= 2010
GROUP BY days_since_ran
ORDER BY days_since_ran LIMIT 50) AS sub;You can see a neat trick for counting wins in line 10.
This is structured as a nested query because the inner SELECT does the counting with runners grouped by days_since_ran, while the outer SELECT calculates percentages using the counted totals per group. I find myself using this nested query approach frequently – counting in the inner and calculating in the outer.
The first 15 lines of the resulting table looks like this:
+----------------+------------+-----------+-------------+
| days_since_ran | race_count | win_count | strike_rate |
+----------------+------------+-----------+-------------+
| 1 | 5051 | 210 | 4.2 |
| 2 | 7250 | 566 | 7.8 |
| 3 | 7839 | 988 | 12.6 |
| 4 | 10054 | 1397 | 13.9 |
| 5 | 13139 | 1705 | 13.0 |
| 6 | 17978 | 2176 | 12.1 |
| 7 | 34955 | 3892 | 11.1 |
| 8 | 29427 | 3064 | 10.4 |
| 9 | 31523 | 3174 | 10.1 |
| 10 | 33727 | 3242 | 9.6 |
| 11 | 36690 | 3411 | 9.3 |
| 12 | 39793 | 3854 | 9.7 |
| 13 | 42884 | 4039 | 9.4 |
| 14 | 61825 | 5771 | 9.3 |
| 15 | 44634 | 4303 | 9.6 |Here we can see that Strike Rate has an interesting peak around 3-7 days since last run. But is this the same for handicaps and non-handicaps ? We can answer that question easily by adding an extra WHERE clause to slice and dice the data. We insert this after the WHERE on line 16:
handicap = 1 ANDrerun the SQL then switch it to:
handicap = 0 ANDand run it again.
We can then paste the output into three text files, import each into Excel, and turn it into a chart:
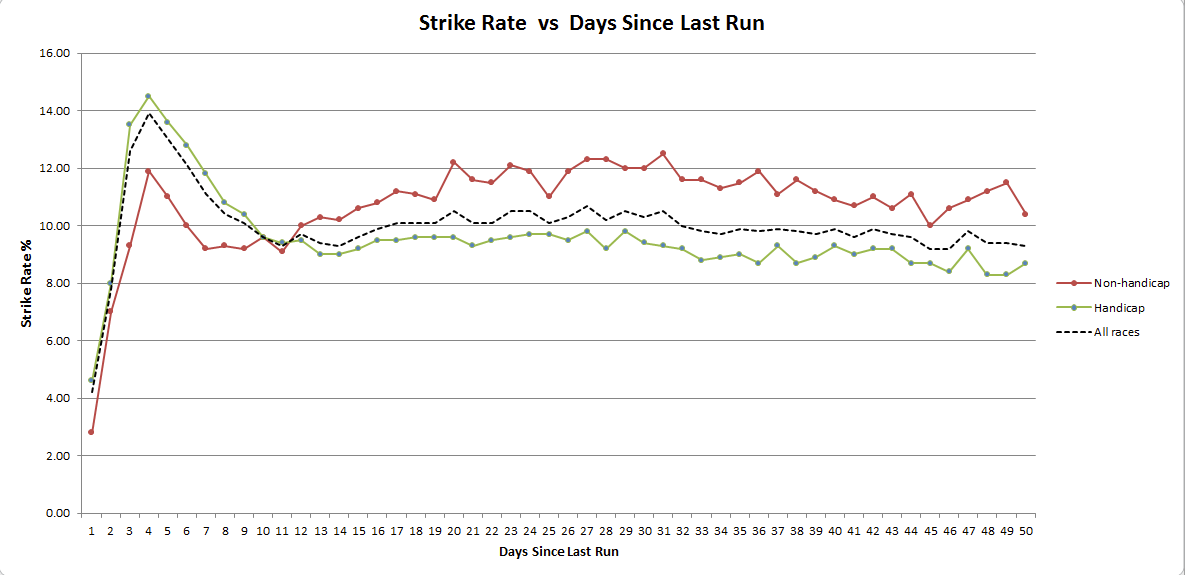
We can see that the quick turnaround Strike Rate peak is most pronounced in handicaps. But for non-handicaps the notable feature is really a lowering of Strike Rate in the 7-14 day range. It’s also interesting to see that handicaps generally have a lower Strike Rate than non-handicaps, perhaps due to field size trends. And as you would expect, running within one or two days of a prior run is rarely a good idea !
But there’s an even better way to structure a query to return the data for all races, handicaps and non-handicaps by adding the handicap field to both SELECT clauses and the GROUP BY with a ROLLUP for good measure:
SELECT
sub.days_since_ran,
sub.handicap,
sub.race_count,
sub.win_count,
round(sub.win_count / sub.race_count * 100, 1) AS strike_rate
FROM (
SELECT
days_since_ran,
handicap,
COUNT(*) as race_count,
COUNT(IF(finish_position = 1, 1, NULL)) AS win_count
FROM
historic_runners_beta
JOIN
historic_races_beta
USING(race_id)
WHERE
days_since_ran IS NOT NULL AND
year(meeting_date) >= 2010
GROUP BY days_since_ran, handicap WITH ROLLUP
ORDER BY days_since_ran, handicap LIMIT 150) AS sub;The first 15 lines of the resulting table looks like this:
+----------------+----------+------------+-----------+-------------+
| days_since_ran | handicap | race_count | win_count | strike_rate |
+----------------+----------+------------+-----------+-------------+
| NULL | NULL | 1496886 | 145734 | 9.7 |
| 1 | NULL | 5051 | 210 | 4.2 |
| 1 | 0 | 1292 | 36 | 2.8 |
| 1 | 1 | 3759 | 174 | 4.6 |
| 2 | NULL | 7250 | 566 | 7.8 |
| 2 | 0 | 1580 | 110 | 7.0 |
| 2 | 1 | 5670 | 456 | 8.0 |
| 3 | NULL | 7839 | 988 | 12.6 |
| 3 | 0 | 1671 | 155 | 9.3 |
| 3 | 1 | 6168 | 833 | 13.5 |
| 4 | NULL | 10054 | 1397 | 13.9 |
| 4 | 0 | 2300 | 274 | 11.9 |
| 4 | 1 | 7754 | 1123 | 14.5 |
| 5 | NULL | 13140 | 1705 | 13.0 |
| 5 | 0 | 3101 | 341 | 11.0 |
| 5 | 1 | 10039 | 1364 | 13.6 |where the rows with handicap = NULL represent the All Races data. While this is less convenient for importing into Excel to make a chart, it is closer to what you may want as a data mapping table for normalizing data to be passed onto a ML system. The top double NULL row gives the Strike Rate for all runners in all races of all types irrespective of days_since_ran as 9.7% – a useful baseline number.
A question for the reader. If the average Strike Rate for all runners in all races of all types is 9.7%, can you use that information to calculate the average number of runners per race ? And what simple one liner query would you use to check your result ? Answers in the comments please 🙂
The final point to tie up is what if you want to use this as a days_since_ran to Strike Rate conversion so that you can present normalized data to your downstream ML system. The simplest solution is to store this data back into the database as a data mapping table by prefixing the outer SELECT with:
DROP TABLE IF EXISTS days_since_ran_x_strike_rate;
CREATE TABLE days_since_ran_x_strike_rate(
days_since_ran int(4),
handicap tinyint(1),
race_count int(6),
win_count int(6),
strike_rate decimal(4,1));
INSERT INTO days_since_ran_x_strike_rate
SELECT
...You can then use this data mapping table for days_since_ran to Strike Rate conversion by performing a JOIN as follows (incomplete code):
SELECT
strike_rate
FROM
daily_runners
JOIN
days_since_ran_x_strike_rate
USING(days_since_ran)To make this work reliably is a little more complex because once over 50 days you need to bucket day ranges or perhaps have a single bucket for > 50 with the LIMIT 50 removed, which in turn means working CASE into your SQL.
For automation, you can set the whole thing up as a stored procedure which you run daily as a Windows scheduled job or Linux cron job, shortly after your daily database update.
Can you run Smartform on the Raspberry Pi?
By bw_admin on Monday, November 2nd, 2020(Guest post by Mike Houghton, Betwise developer)
As part of the new Smartform beta process, we have recently been playing with the Raspberry Pi 4, a tiny Linux computer that we suspect needs little introduction but which has taken great strides in the last year or so.
If you have until now been unaware of the Raspberry Pi, well, what is it?
It’s best described as a Linux computer running on a mobile phone processor that is the emotional descendant of the classic BBC Micro. It emerged from an educational computing project to produce a small, very cheap Linux computer for the education market, suitable for tinkering with electronics and robotics, and to provide young programmers with the kind of open-ended computing experience that its founders remembered from the 1980s and believed was missing in the world of games consoles.
Over the years it has appeared in several form factors, including an absolutely tiny, keyfob-sized computer that was given away as a freebie stuck to the front cover of a magazine!
The most recent product — today’s brand new Raspberry Pi 400 — is perhaps the most loudly reminiscent of those 1980s computers. It’s a very powerful little computer, hidden in a neat little keyboard, for less than £100, that can plug into a modern television.
Despite their low cost, these aren’t particularly underpowered computers — within certain limits. The Raspberry Pi 4 is a 64 bit machine equipped with an ARM processor and up to 8GB of RAM.
So, can it run Smartform?
Yes!
We have experimented with the Raspberry Pi 2 and Pi 3 over the years and found those machines rather less satisfactory for giant databases. Of course, since it’s a petite Linux machine, the MySQL and shell-scripts approach of our Linux product has always worked, if you’ve been prepared to put up with a lot of fiddling and a not particularly quick response.
In 2020, we think the Pi 4 is fast and capable enough that we’re offering some early support for it.
Is it actually fast?
Ye–eees.
The 8GB ram Pi 4 is broadly comparable in CPU performance terms to Amazon’s a1.large EC2 instance. No slouch.
There’s a big caveat here, though. As a tiny little computer sold for a tiny little price, the storage is tiny little memory cards: Micro SD. The kind you use in mobile phones.
SD and Micro SD cards are very fast for reading in a sequential fashion — no problem for a HD movie — but they are very slow for random-access reads and writes, so loading a database with huge number of INSERT statements isn’t fast.
But once your database is loaded, SD read speeds with good modern cards (we’ve had good results with SanDisk Ultra micro SD) are not so bad for tinkering. Just not fast enough to use as your main analytics tool.
For much faster disk performance, the Pi 4 and Pi 400 are the first machines to offer USB3, so external disks can be quick — and while the Pi normally boots from the MicroSD card, you can set them up to boot from a USB 3 drive.
We have had good results with a UASP caddy with an SSD drive inside. Here’s a great video from Jeff Geerling to explain:
At this point, you could have an 8GB RAM, 64-bit, SSD-equipped computer for not much more than £100 that can be set up to run quietly in a corner and do your Smartform tasks for you on a schedule.
Then you can connect to it over WiFi from your database tools, or plug a monitor, keyboard and mouse in and use it as a dedicated mini desktop.
What is different to an ordinary Linux PC?
Not all that much, actually, aside from the SD card aspect. And the price.
The key difference is that the Raspberry Pi has an ARM processor (which is why it is cheap), instead of an Intel processor.
So you might be compiling a few things yourself, perhaps, and we have our own Raspberry Pi builds of our new Smartform updater.
Why use this rather than a PC?
Apart from having to share disk space with the family’s FPS game collection? We like the idea of Smartform as an appliance, of course; Smartform in a tiny box.
More generally we think an interesting thing about the Pi 4 is the possibility to inexpensively dedicate a machine to a single task such as machine learning (the Pi 4 has a GPU).
Also the potential to use more than one of them in a small cluster. The Pi 4 supports gigabit ethernet, so it is not too tricky to imagine adding more computing power by distributing tasks over multiple machines.
So how do I get started?
You can set up your Raspberry Pi either by following the instructions that come with your Pi, or on their website.
Installing Smartform is mostly the same as installing it for Linux, except for the different updater binary. You can get the updater binary and read a little bit more here.
What does the future hold for Smartform on the Pi?
I think we’re not sure yet.
For my own perspective, I’m looking forward to a time when a Pi 4 installation is my reference implementation for the loader and the code.
Also I am particularly interested in the possibility of making an installer that can configure a turnkey appliance Smartform setup on a Pi without any user interaction at all; we know it can be a little fiddly to get Smartform going, so it would be great to have this sort of tool.
That appliance setup could be used as the basis of an off-the-shelf betting robot or machine learning project.
(Plus, using the new historic_runners_insights table in Smartform you can implement simple systems in pure SQL, no need to delve into machine learning unless you want to — Colin)
What would you want to try?
Looking at the importance of variables.
By Steve Tilley on Sunday, August 23rd, 2020This article shows how you can compare how important different variables are from the historical insights table in Smartform.
The article provides a skeleton where you can test other variables for other types of races. I have put the whole R code at the end of article
In the Historical Insights table are some new variables. I am going to look at a group of these.
- won_LTO, won_PTO, won_ATO, placed_LTO, placed_PTO, placed_ATO, handicap_LTO. handicap_PTO, handicap_ATO, percent_beaten_LTO, percent_beaten_PTO and percent_beaten_ATO
These are quite self-explanatory with LTO meaning last time out, PTO is penultimate time out and ATO, antepenultimate time out or three runs ago.
I have chosen to look at all UK all-weather handicaps since January 1st 2017. I have chosen handicaps as the runners will generally have several previous runs. I have guaranteed this by only selecting horses that have more than three previous runs.
I will be using a package called Boruta to compare the variables so you will need to install that if you do not already have it.
library("RMySQL")
library("dplyr")
library("reshape2")
library("ggplot2")
library("Boruta")As always I do a summary of the data. Here I need to deal with NA values, and there are some in the historic_runners.finishing_position field. Because I have over 55000 rows of data and only 250 NAs I have deleted those rows.
smartform_results <- na.omit(smartform_results)I need to add a variable to tell me if the horse has won the race or not, I have called this winner. It will act as a target for my other variables.
smartform_results$Winner = ifelse(smartform_results$finish_position < 2,1,0)Then I need to select the variables I wish to compare in their importance in predicting the winner variable.
allnames=names(smartform_results)
allnames
[1] "course" "meeting_date" "race_id" "race_type_id" "race_type"
[6] "distance_yards" "name" "finish_position" "starting_price_decimal" "won_LTO"
[11] "won_PTO" "won_ATO" "placed_LTO" "placed_PTO" "placed_ATO"
[16] "handicap_LTO" "handicap_PTO" "handicap_ATO" "percent_beaten_LTO" "percent_beaten_PTO"
[21] "percent_beaten_ATO" "prev_runs" "Winner" This gives me a list of all the variables in my data.
I must admit when downloading data from a database I like to include a variety of race and horse variables to make sure my selection criteria have worked properly. For example race and horse names. I now need to remove these to make a list of the variables I need.
I can see I have 23 variables, and from the output of allnames I can work out which ones I don’t need and get their numerical indices. I find it easier to work with numbers than variable names at this stage. Notice I’ve removed my target variable, winner.
datalist=allnames[-c(1,2,3,4,5,6,7,8,9,22,23)]
> datalist
[1] "won_LTO" "won_PTO" "won_ATO" "placed_LTO" "placed_PTO" "placed_ATO"
[7] "handicap_LTO" "handicap_PTO" "handicap_ATO" "percent_beaten_LTO" "percent_beaten_PTO" "percent_beaten_ATO"
> target=allnames[23]
> target
[1] "Winner"So datalist contains all the variables I am testing and target is the target that they are trying to predict.
I use these to produce the formula that R uses for most machine learning and statistical modelling
mlformula <- as.formula(paste(target,paste(datalist,collapse=" + "), sep=" ~ "))All this rather unpleasant looking snippet does is produce this formula.
Winner ~ won_LTO + won_PTO + won_ATO + placed_LTO + placed_PTO +
placed_ATO + handicap_LTO + handicap_PTO + handicap_ATO +
percent_beaten_LTO + percent_beaten_PTO + percent_beaten_ATO
This means predict the value of Winner using all the variables after the ~ symbol.
This translates as, predict winner using all the variables named after the ~ symbol.
At last, we can use Boruta to see which of our variables is the most important. I am not going to give a tutorial in using Boruta. There are numerous ones available on the internet. There are various options you can use. I have just run the simple vanilla options here. It will take a little while to run depending on the speed of your machine
Once it has finished, you can do one more thing. This line forces Boruta to decide if variables are important.
final.boruta <- TentativeRoughFix(boruta.train)Here is the output. Do not worry if your numbers do not exactly match they should be similar.
meanImp medianImp minImp maxImp normHits decision
won_LTO 17.454272 17.336936 15.2723929 19.681327 1.0000000 Confirmed
won_PTO 11.858611 11.847156 9.6080635 13.915011 1.0000000 Confirmed
won_ATO 10.646576 10.571548 8.5119054 12.529334 1.0000000 Confirmed
placed_LTO 22.967911 23.035708 20.2490144 25.244789 1.0000000 Confirmed
placed_PTO 21.871156 21.946160 19.2961340 24.466836 1.0000000 Confirmed
placed_ATO 20.242410 20.231261 17.3522156 22.853500 1.0000000 Confirmed
handicap_LTO 2.437791 2.360027 -0.9938698 5.342918 0.4747475 Confirmed
handicap_PTO 7.568926 7.620271 4.2983632 11.147914 1.0000000 Confirmed
handicap_ATO 9.521332 9.551424 5.7088247 13.628699 1.0000000 Confirmed
percent_beaten_LTO 34.039496 34.076843 30.2324486 38.099816 1.0000000 Confirmed
percent_beaten_PTO 27.804420 27.716601 24.2223531 31.686299 1.0000000 Confirmed
percent_beaten_ATO 22.990647 23.121783 19.8763102 25.945583 1.0000000 ConfirmedAll the variables are confirmed as being important related to the target variable. The higher the value in the first column the more important the variable. Here the percent beaten variables seem to do well while the handicap last time out is only just significant.
You can see this better in a graph.
plot(boruta.train, xlab = "", xaxt = "n")
lz<-lapply(1:ncol(boruta.train$ImpHistory),function(i) boruta.train$ImpHistory[is.finite(boruta.train$ImpHistory[,i]),i])
names(lz) <- colnames(boruta.train$ImpHistory)
Labels <- sort(sapply(lz,median))
axis(side = 1,las=2,labels = names(Labels), at = 1:ncol(boruta.train$ImpHistory), cex.axis = 0.7)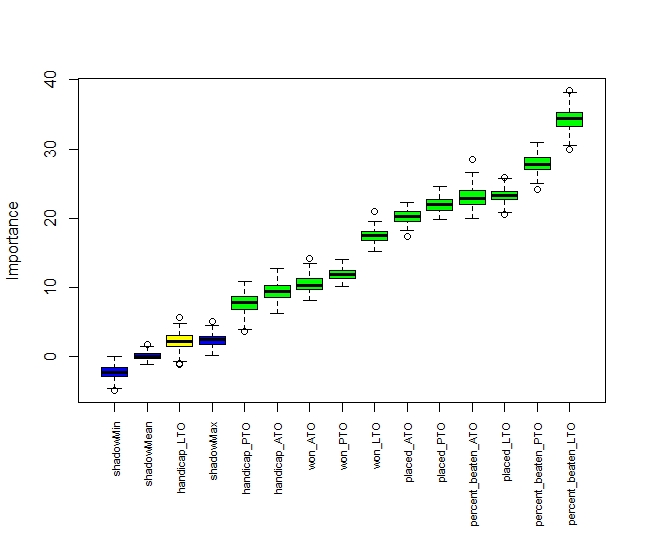
Handicap LTO is yellow as that is only just significant. The rest are green and are significant. The three blue variables are what we might expect by chance, read up more on Boruta for more details..
It is also worth noting for each variable apart from handicap LTO the most recent race is the most significant. SO LTO is more significant than PTO which is more significant than LTO.
By looking at variable importance, we can concentrate our modelling on those that are most important to our outcome
The importance of variables will vary with the type of race you are studying. What is important to all-weather handicaps may well not be important in long-distance Novice Chases.
Hopefully, you can use the attached script as a blueprint for your particular analyses.
library("RMySQL")
library("dplyr")
library("reshape2")
library("ggplot2")
library("Boruta")
con <- dbConnect(MySQL(),
host='127.0.0.1',
user='smartform',
password='*************',
dbname='smartform')
sql1 <- paste("SELECT historic_races.course,
historic_races.meeting_date,
historic_races.race_id,
historic_races.race_type_id,
historic_races.race_type,
historic_races.distance_yards,
historic_runners.name,
historic_runners.finish_position,
historic_runners.starting_price_decimal,
historic_runners_insights.won_LTO,
historic_runners_insights.won_PTO,
historic_runners_insights.won_ATO,
historic_runners_insights.placed_LTO,
historic_runners_insights.placed_PTO,
historic_runners_insights.placed_ATO,
historic_runners_insights.handicap_LTO,
historic_runners_insights.handicap_PTO,
historic_runners_insights.handicap_ATO,
historic_runners_insights.percent_beaten_LTO,
historic_runners_insights.percent_beaten_PTO,
historic_runners_insights.percent_beaten_ATO,
historic_runners_insights.prev_runs
FROM smartform.historic_runners
JOIN smartform.historic_races USING (race_id)
JOIN smartform.historic_runners_insights USING (race_id, runner_id)
WHERE historic_races.meeting_date >= '2019-01-01' AND historic_races.race_type_id=15 AND historic_runners_insights.prev_runs>3 AND historic_races.course!='Dundalk'AND historic_races.handicap=1", sep="")
smartform_results <- dbGetQuery(con, sql1)
View(smartform_results)
dbDisconnect(con)
smartform_results <- na.omit(smartform_results)
smartform_results$Winner = ifelse(smartform_results$finish_position < 2,1,0)
allnames=names(smartform_results)
allnames
datalist=allnames[-c(1,2,3,4,5,6,7,8,9,22,23)]
datalist
target=allnames[23]
target
mlformula <- as.formula(paste(target, paste(datalist,collapse=" + "), sep=" ~ "))
mlformula
print(mlformula)
set.seed(123)
boruta.train <- Boruta(mlformula, data =smartform_results, doTrace = 2)
print(boruta.train)
final.boruta <- TentativeRoughFix(boruta.train)
boruta.df <- attStats(final.boruta)
print(boruta.df)
plot(boruta.train, xlab = "", xaxt = "n")
lz<-lapply(1:ncol(boruta.train$ImpHistory),function(i) boruta.train$ImpHistory[is.finite(boruta.train$ImpHistory[,i]),i])
names(lz) <- colnames(boruta.train$ImpHistory)
Labels <- sort(sapply(lz,median))
axis(side = 1,las=2,labels = names(Labels), at = 1:ncol(boruta.train$ImpHistory), cex.axis = 0.7)Tongue tie on the 1000 Guineas favourite – should we be worried?
By colin on Sunday, June 7th, 2020Reviewing the 1000 Guineas today, I could not help but be drawn to the favourite, Quadrilateral, unbeaten daughter of Frankel, arguably the most impressive winner of the 2,000 Guineas, ever.
3/1 is on offer, a short enough price. But if she is anywhere near as good as Frankel, that’s a long price indeed!
But what is this in the declarations? First time tongue strap.
Should we be worried?
A little bit (ok quite a lot) of data manipulation in Smartform enables us to build a table of runner records with counts of when a tongue strap was applied, such that we can group records into all, tongue strap and first time tongue strap. A further grouping of these records by trainer reveals the following records for Roger Charlton, Quadrilateral’s own handler:

You’ll have to click on the image to see this properly, it’s a table View straight out of R, but long story short, rounding those figures to the nearest whole number, here’s the picture for Roger Charlton:
- 17% overall win strike
- 12% win strike when applying tongue strap
- 9% win strike when applying first time tongue strap
So the answer to the question “Should we be worried?” has to be “Yes” (unless my rapid calculations have gone awry somewhere!). Does this mean the favourite can’t win? Of course not. But can’t be betting at such short odds, personally, with such doubts and no real explanation at hand.
The only references I can find from the trainer are his bullish sounding quote in today’s Post:
“We’re looking forward to it. She looks magnificent. She’s a big, strong filly and these are exciting times. I hope she can run as well as she did the last time she went to Newmarket.”
And the rather anodyne message from the trainer’s own blog:
“The fourth runner to head out is Quadrilateral at Newmarket in the ‘Qipco 1000 Guineas Stakes’ for her owner Prince Khalid Abdullah. The daughter of Frankel had three runs as a two year old last season in which she maintained an unbeaten record throughout. It included the Group 1 ‘bet365 Fillies Mile’ at Newmarket which landed her with an official rating of 114. The race holds 15 competitive runners as to be expected and we have a draw of 6. Jason Watson takes the ride. She has wintered very well and remains a filly with an impressive physique, who holds her condition well. There is a little bit more rain expected between now and the race which won’t bother her and we are excited to get her on the track.”
Nothing about the reasoning behind the statistically negative tongue tie, which I suppose is to be expected in the run up to a big race with so much at stake.
Fingers crossed she runs well, but will have to take a watching brief, and will be looking elsewhere for some each way value.
Betwise daily oddsline for UK and Irish horseracing
By colin on Tuesday, June 2nd, 2020We’ve been experimenting with automatically generated oddslines for a while at Betwise, in fact that was the premise of the book Automatic Exchange Betting, published in 2007!
What is an oddsline? Simple, it’s a set of prices, the same as a bookmaker offers you, but with a set of chances for all contenders that is as close to the actual chance (or probability) each horse has of winning a race. The difference is that a fair oddsline adds up to 100% probability, whereas a bookmaker will build in a margin of profit across all the odds on offer (or overround). Moreover, a bookmaker will adjust prices based on weight of money for each contender. Exchange prices are simply a function of weight of money with the market determining back and lay prices, with the Exchange taking a commission. The more participants in the market, and the greater the weight of money, the more chance that the probabilities will add up to the magic 100% (except of course that the Exchange margin on winning bets will damage that “fair” book).
The art of bookmaking involves creating such prices from scratch based on knowledge of the market, the contenders, what prices others are offering, whatever risk the bookmaker wants to take, and then adjusting the prices according to weight of money, with possibly more attention being paid to “smart” money!
However, in the age of Artificial Intelligence, both bookmaker and punter can do better. Or can they?
To automate an oddsline, there is usually a combination of a machine learning algorithm to make predictions based on past data, some element of factoring in the probabilities from the market (to represent the element of weight of money), and last but not least, an algorithm to ensure that the predictions from the oddsline are relatable to the odds on offer. In other words, that the odds from the oddsline are realistic and sum to 100%. Machine learning and artificial intelligence is all the rage now, but it isn’t that new. Whether expert opinion or machine learning is used to form your view, Smartform was created off the back of Automatic Exchange Betting for bettors who value the ability to use a programmatic database and programming tools for gaining a personal edge of this nature.
The end use is the same for either an automated or “expert” oddsline – if a certain horse’s odds are higher than what the “fair” odds should be then that’s worth a bet, if the horse’s odds are lower, conversely, then the horse may be worth laying.
At least that is the theory. In practice, there are a million things that can go wrong!
While lockdown was in progress, we were busy creating an automated public oddsline, a free version of the one that we’ve been developing for a while, that you can find here every day before Noon:
https://www.betwise.co.uk/oddsline/
Feel free to download, review and even use at your own risk.
Bookmaker vs Betfair Odds Comparison
By Tom Bardrick on Monday, July 8th, 2019This blog will look into:
- How to process the output of a query from the SmartForm database into a dataframe
- An example of how to carry out analysis on this data, in particular looking at the relationship between forecast prices / starting prices and investigating how overround varies for bookmakers odds compared to odds offered by Betfair.
Setting up Connection to Database
Connecting to MySQL server (as shown in the previous article below).
import pymysql
connection = pymysql.connect(host='localhost', user='root', passwd = '*****', database = 'smartform')
cursor = connection.cursor()
Querying the Database
Running a query to merge ‘historic_runners’ table with the ‘historic_races’ table. This will be done using an inner join to connect the runners data with the races data…
- SELECT the race name and date (from historic_races) and all runner names, the bookies’ forecast price and their starting price (from historic_runners)
- Using an INNER JOIN to merge the ‘historic_races’ database to the ‘historic_runners’ database. Joining on ‘race_id’
- Using WHERE (with CAST AS due to data type) clause to only search for races in 2018 AND only returning flat races
query = ''' SELECT historic_races.race_name, historic_races.meeting_date, historic_runners.name, historic_runners.forecast_price_decimal, historic_runners.starting_price_decimal
FROM historic_races
INNER JOIN historic_runners ON historic_races.race_id = historic_runners.race_id
WHERE (CAST(historic_races.meeting_date AS Datetime) BETWEEN '2018-01-01' AND '2018-12-31')
AND
(historic_races.race_type = 'Flat')
'''
cursor.execute(query)
rows = cursor.fetchall()
Converting Query Result to a Dataframe
Converting the query results (a tuple of tuples) into a pandas dataframe and printing the first 15 instances to check the conversion was carried out as expected. The pandas package will need to be imported in order to do this. This can be done by running ‘pip install pandas’ in the same way ‘pymysql’ was installed in the previous article below.
import pandas as pd
# for convenience of future queries the following code enables any SELECT query and conversion to dataframe without direct input of column names
start = query.find('SELECT') + 7
end = query.find('\n FROM', start)
names = query[start:end].split(', ')
df = pd.DataFrame(list(rows), columns=names)
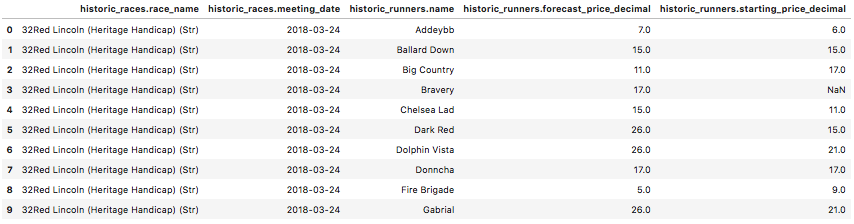
df.head(10)
If wanting to output the dataframe into excel/csv at any time, this can be done with either of the following commands:
df.to_excel("output.xlsx")
df.to_csv("output.csv")
DataFrame Pre-processing
Checking the dimensions of the dataframe
print('DataFrame Rows: ', df.shape[0], '\nDataFrame Columns: ', df.shape[1])
DataFrame Rows: 50643
DataFrame Columns: 5
Checking missing values of the dataframe
print('Number of missing values in each column: ', df.isna().sum())
Number of missing values in each column: race_name 0
race_date 0
runner_name 0
forecast_price 1037
starting_price 4154
dtype: int64
Keeping rows with only non-missing values and checking this has worked
df = df[pd.notnull(df['historic_runners.forecast_price_decimal'])]
df = df[pd.notnull(df['historic_runners.starting_price_decimal'])]
df.isna().sum()
race_name 0
race_date 0
runner_name 0
forecast_price 0
starting_price 0
dtype: int64
Checking the new dimensions of the dataframe
print('DataFrame Rows: ', df.shape[0], '\nDataFrame Columns: ', df.shape[1])
DataFrame Rows: 46374
DataFrame Columns: 5
Approximately 3700 rows lost to missing data
Producing a Distribution Plot
Seaborn is a statistical data visualisation package and can imported in the same way ‘pandas’ and ‘pymysql’ were installed. From this package different types of plots can be produced by simply inputting our data. (matplotlib can also be installed to adjust the plot size, titles, axis etc…).
The following code produces distribution plots:
* The distribution of the forecast price for all runners
* The distribution of the starting price for all runners
This allows us to have a visual understanding of the most common forecasted and starting prices and how these prices are distributed.
import seaborn as sns; sns.set(style="white", color_codes=True)
import matplotlib.pyplot as plt
%matplotlib inline
# '%matplotlib inline' this line enables plots to be shown inside of the jupyter environment
plt.figure(figsize = (12,6))
sns.distplot(df['historic_runners.forecast_price_decimal'], kde = True) # distribution plot for forecasted prices
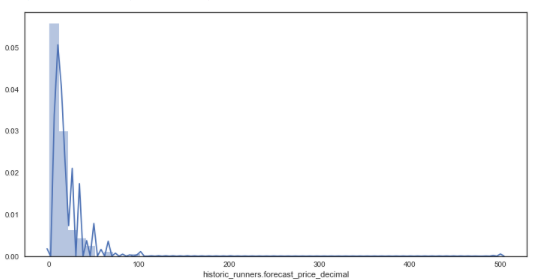
plt.figure(figsize = (12,6))
sns.distplot(df['historic_runners.starting_price_decimal']) # distribution plot for starting prices
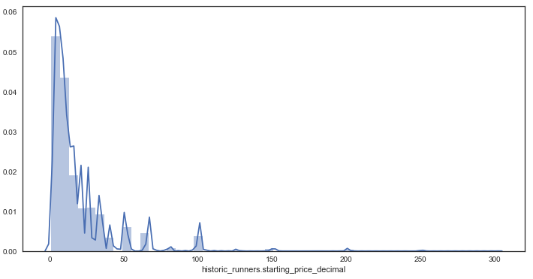
From the distribution plots it is very clear that the data is skewed due to some very large outsider prices of some horses. Wanting to investigate how the majority of prices are related to forecasted prices, these outsiders will be removed and the analysis will only focus on those with a prices below 16/1.
Having observed horse racing markets for a while it appears that many outsiders’ prices are very sensitive to market forces and can change between 66/1 and 200/1 with only little market pressure, therefore these data points have been removed for this analysis.
# creating new dataframe with prices <= 16/1
df_new = df.loc[((df['historic_runners.forecast_price_decimal'] <= 17.0) & (df['historic_runners.starting_price_decimal'] <= 17.0))]
sns.distplot(df_new['historic_runners.forecast_price_decimal']) # new distribution plot of forecasted prices
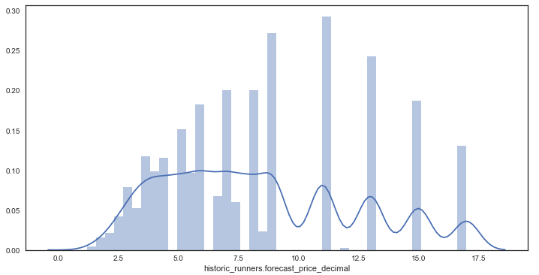
- From the data it can be seen that the prices appear discrete in some places yet continuous in others, this is likely due to the traditional way of bookmakers formulating odds, favouring some odds (e.g. 16/1) over others (e.g. 19/1).
- Also, the data looks far less skewed after the removal of large outsiders.
Producing a Scatter Plot
In order to have a look at how these variables may relate to one another, a scatter plot is constructed to plot both distributions against one another.
sns.jointplot(x="historic_runners.forecast_price_decimal", y="historic_runners.starting_price_decimal", data=df_new) # plotting forecasted price against starting price
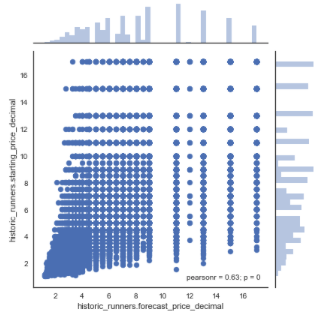
As seen, these variables appear to have a moderate to strong positive linear correlation with a pearson correlation coefficient of 0.63.
Due to the large difference between certain higher prices and many points being plotted on top of one another it can be difficult to visualise the relationships between the two variables. A heatmap can be a helpful tool in this case and can be simply produced by adding in the parameter ‘kind=”kde”‘.
sns.jointplot(x="historic_runners.forecast_price_decimal", y="historic_runners.starting_price_decimal", data=df_new, kind="kde");
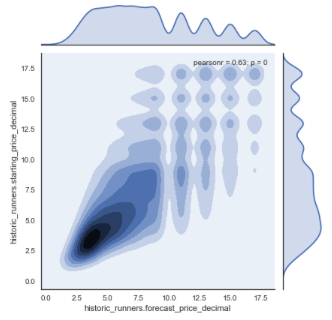
As shown, by the map, there is a high density of prices between 0 and 10/1 with most prices being between 6/4 and 4/1. The correlation appears to get somewhat weaker as the prices increase however this may in part be accredited to the use of more decimal places for lower priced horses.
Assessing Accuracy of Forecasted Prices
The given forecasted price can be used to assess the accuracy of more sophisticated predictive models. This can be done by comparing the accuracy of the new model to the accuracy of the forecasted prices.
The following code outlines a way of using the scikit learn package to calculate an R-Squared value. The R-squared is a measure of how much variance of a dependent variable is explained by an independent variable and is a way of assessing how ‘good’ a model is.
import sklearn
from sklearn.metrics import r2_score
print(r2_score(df_new['historic_runners.forecast_price_decimal'], df_new['historic_runners.starting_price_decimal']))
0.3075885002150722
This is a relatively low R-Squared value and it is likely to be improved upon with a more sophisticated model.
Betfair Price Analysis from Smartform Database
Another very insightful data source from Smartform is the historic Betfair prices table which can also be merged with the historic_races and historic_runners table. As shown below, there is a great number of variables that have been extracted from the Betfair exchange for pre-race and in-play price movements. (More can be read about this data source here).
query = ''' SELECT race_id, name, starting_price,
historic_betfair_win_prices.bsp, historic_betfair_win_prices.av_price, historic_betfair_win_prices.early_price,
historic_betfair_win_prices.ante_maxprice, historic_betfair_win_prices.ante_minprice, historic_betfair_win_prices.inplay_max,
historic_betfair_win_prices.inplay_min, historic_betfair_win_prices.early_traded, historic_betfair_win_prices.total_traded,
historic_betfair_win_prices.inplay_traded
FROM historic_races
JOIN historic_runners USING (race_id) join historic_betfair_win_prices ON race_id=sf_race_id and runner_id = sf_runner_id
WHERE (CAST(historic_races.meeting_date AS Datetime) BETWEEN '2018-01-01' AND '2018-12-31')
AND
(historic_races.race_type = 'Flat')
'''
cursor.execute(query)
rows = cursor.fetchall()
df_bf = pd.DataFrame(list(rows), columns=['race_id','runner_name','SP','bsp', 'av_price', 'early_price', 'ante_maxprice', 'ante_minprice', 'inplay_max',
'inplay_min', 'early_traded', 'total_traded', 'inplay_traded'])
df_bf.head(15)
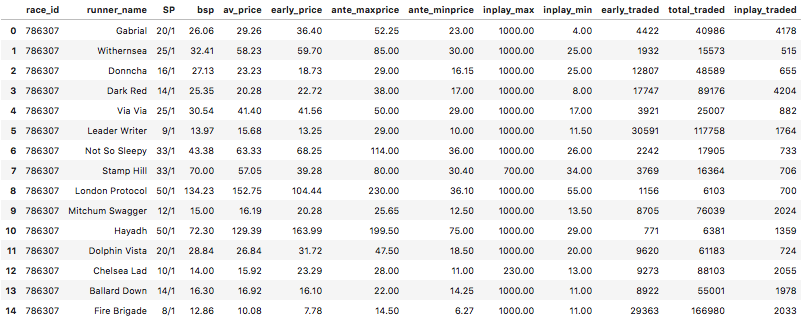
Similar to before, analysis can be carried out on the early price and the starting price but this time using Betfair prices, to assess if there are still similar results on the Betfair Exchange.
import seaborn as sns
%matplotlib inline
# 'matplotlib inline' this line enables plots to be shown inside of a jupyter environment
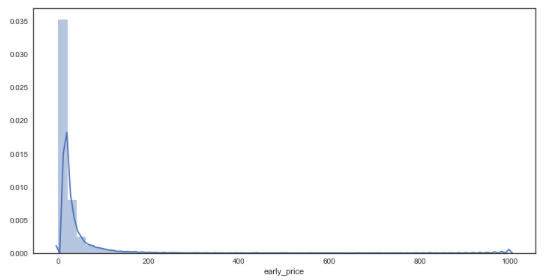
df_bf['early_price'] = df_bf['early_price'].astype('float')
sns.distplot(df_bf['early_price']) # distribution plot for early prices
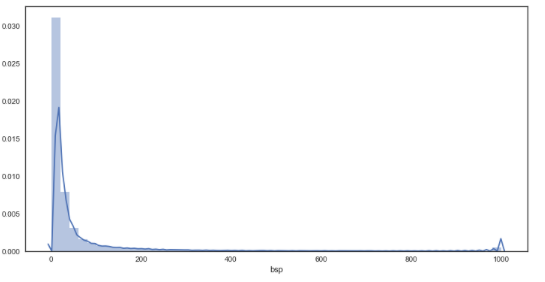
df_bf['bsp'] = df_bf['bsp'].astype('float')
plt.figure(figsize = (12,6))
sns.distplot(df_bf['bsp']) # distribution plot for starting prices
df_bf_new = df_bf.query('early_price <= 200 & bsp <= 200') # creating new dataframe with prices <= 200/1
plt.figure(figsize = (12,6))
sns.distplot(df_bf_new['early_price']) # new distribution plot of forecasted prices
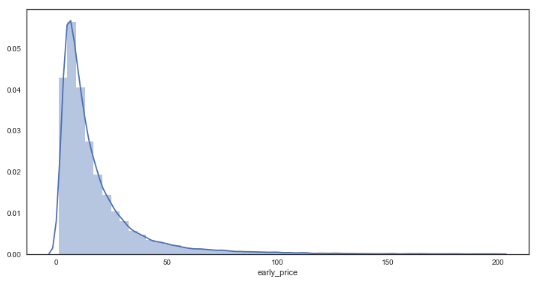
plt.figure(figsize = (12,6))
sns.distplot(df_bf_new['bsp']) # new distribution plot of forecasted prices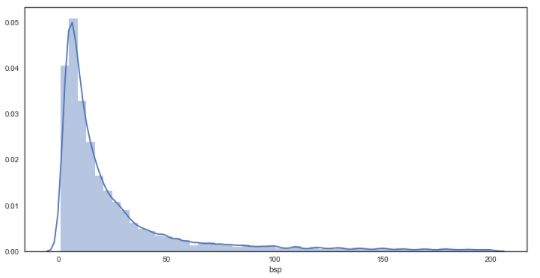
As seen from the graphs, the plots are much smoother in comparison to the bookies’ prices, suggesting a greater granularity in the prices on offer through Betfair. In regards to the distributions, there appears to be little difference between bookmakers and betfair starting prices from visual inspection.
sns.jointplot(x="early_price", y="bsp", data=df_bf_new) # plotting early prices against starting prices
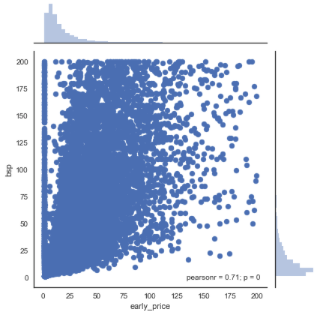
Again, there appears to be a moderate to strong positive linear correlation with a pearson correlation coefficient of 0.71. This increase (from 0.63) is to be somewhat expected given that early prices are being investigated instead of forecast prices. This finding may suggest that early prices are slightly more telling of what the starting price will be (compared to forecast prices).
It should also be noted that there are many really low early prices less than 1, compared to no Betfair starting prices within this range. It is believed that this may be caused by some markets having low liquidity in their early stages and lack of a fully priced market at this point. In order to investigate this further, the effect of overround in these early markets has been analysed below.
How does Overround differ in Betfair markets?
Another interesting aspect of these markets is the amount of overround – or ‘juice’ offered to punters. Overround can be defined as a measure of how much of a margin the bookmaker is taking out of the market in order for themselves to make a profit. Effectively, the higher the overround the worse the odds you are likely to get. In other words the odds are likely to be worse value compared to the true probability of an event happening.
From the analysis above, there were signs that early prices may have a greater overround than starting prices. The following data and analysis has been carried out to see if anything can be inferred about this.
Running the following query calculates the overround for every market (all flat races in 2018) by extracting the implied probability from the odds of each runner.
Overround = the sum of all implied probabilities from every runner – 1.
query = ''' SELECT race_id, SUM(1/historic_betfair_win_prices.early_price)-1 AS 'early_overround', SUM(1/historic_betfair_win_prices.bsp)-1 AS 'SP_overround'
FROM historic_races
JOIN historic_runners USING (race_id) join historic_betfair_win_prices ON race_id=sf_race_id and runner_id = sf_runner_id
WHERE (CAST(historic_races.meeting_date AS Datetime) BETWEEN '2018-01-01' AND '2018-12-31')
AND
(historic_races.race_type = 'Flat')
GROUP BY race_id
'''
cursor.execute(query)
rows = cursor.fetchall()
df_bf_overround = pd.DataFrame(list(rows), columns=['race_id', 'early_price_overround', 'betfair_starting_price_overround'])
df_bf_overround.head(15)
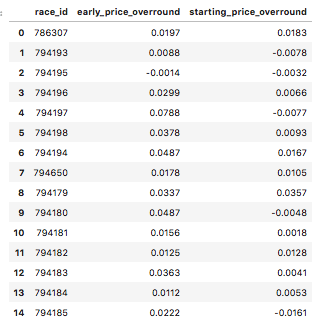
This dataframe consists of the overround for early prices and starting prices on the Betfair exchange for every market (flat race in 2018).
df_bf_overround['early_price_overround'] = df_bf_overround['early_price_overround'].astype('float')
df_bf_overround['starting_price_overround'] = df_bf_overround['starting_price_overround'].astype('float')
sns.distplot(df_bf_overround['early_price_overround']) # distribution plot for early prices
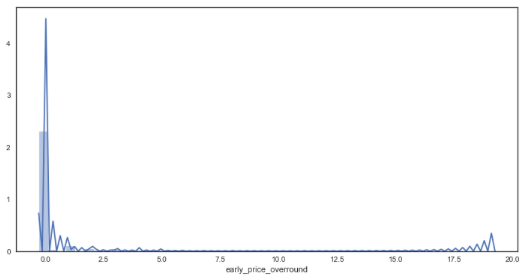
plt.figure(figsize = (12,6))
sns.distplot(df_bf_overround['starting_price_overround']) # distribution plot for early prices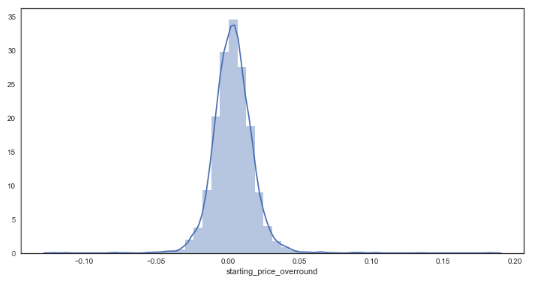
There appears to be some anomalies created via the calculation for early markets. This could perhaps be attributed to prices not yet being offered by the market for some horses within the market. To continue with the analysis, it has been assumed that any market with an overround less than 50% is incomplete and thus will only focus on markets with overrounds below this amount.
df_bf_overround_new = df_bf_overround.query('early_price_overround <= 0.5 & starting_price_overround <= 0.5')overrounds = list(df_bf_overround_new.columns.values)[1:3]
plt.figure(figsize=(12,7))
for overround in overrounds:
sns.distplot(df_bf_overround_new[overround])
plt.title('Distribution of Market Overrounds (Early v Starting Prices)', size = 22)
plt.xlabel('Overround %', size = 16)
plt.legend(labels = overrounds, loc = 'upper left', prop={'size': 14} )
plt.show()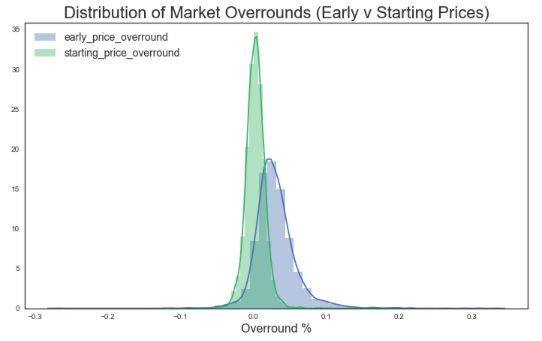
print('Average (mean) overround for early priced markets: ', df_bf_overround_new['early_price_overround'].mean())
Average (mean) overround for early priced markets: 0.03054834814308512
print('Average (mean) overround for starting price markets: ', df_bf_overround_new['starting_price_overround'].mean())
Average (mean) overround for starting price markets: 0.003256390977443608
from scipy import stats
stats.ttest_ind(df_bf_overround_new['early_price_overround'], df_bf_overround_new['starting_price_overround'])
Ttest_indResult(statistic=54.96055888606393, pvalue=0.0)
This T-test result (p-value of 0.0) confirms that there is a statistical difference between the means of each sample i.e. there is a difference between the averages of overround early and starting prices
Betfair starting prices appear to have approximately 0.0% overround on average, compared to an average 3% on their early prices.
From this it could be inferred that starting prices have a better overround on average than early prices – meaning that punters are in effect more likely to get ‘more for their money’ if entering the market directly before post time compared to betting on early prices. This may be because there is a greater amount of liquidity in the markets at this point in time.
Finally, how does starting price overround differ between bookmaker and exchange prices?
In order to retrieve the data to answer this question, two separate queries were run from the database for simplicity and then their dataframes concatenated as shown below:
First, extracting the Betfair starting prices into a dataframe…
query = ''' SELECT race_id, SUM(1/historic_betfair_win_prices.bsp)-1 AS 'SP_overround'
FROM historic_races
JOIN historic_runners USING (race_id) join historic_betfair_win_prices ON race_id=sf_race_id and runner_id = sf_runner_id
WHERE (CAST(historic_races.meeting_date AS Datetime) BETWEEN '2018-01-01' AND '2018-12-31')
AND
(historic_races.race_type = 'Flat')
GROUP BY race_id
'''
cursor.execute(query)
rows = cursor.fetchall()
df_bf_sp_overround = pd.DataFrame(list(rows), columns=['race_id', 'betfair_starting_price_overround'])
df_bf_sp_overround.head(15)
Next, extracting the bookies’ starting prices into a dataframe…
query = ''' SELECT race_id, SUM(1/starting_price_decimal)-1 AS 'early_overround'
FROM historic_races join historic_runners using (race_id)
WHERE (CAST(historic_races.meeting_date AS Datetime) BETWEEN '2018-01-01' AND '2018-12-31')
AND
(historic_races.race_type = 'Flat')
GROUP BY race_id
'''
cursor.execute(query)
rows = cursor.fetchall()
df_bookies_sp_overround = pd.DataFrame(list(rows), columns=['race_id', 'bookies_starting_price_overround'])
df_bookies_sp_overround.head(15)
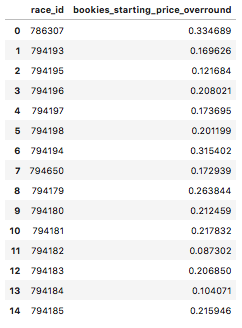
Then, merging both dataframes together, joining them on the variable ‘race_id’…
#Merging the two dataframes on race_id
df_merge_col = pd.merge(df_bookies_sp_overround, df_bf_sp_overround, on='race_id')
print('betfair df size :', df_bf_sp_overround.shape, 'bookies df size :', df_bookies_sp_overround.shape, 'total size :', df_merge_col.shape)
betfair df size : (4829, 2) bookies df size : (4863, 2) total size : (4829, 3)
(This merge had a loss of 34 rows. It appears the Betfair data had more races in this time period than bookies had priced up in this time period).
df_merge_col.head()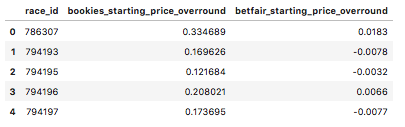
import matplotlib.pyplot as plt
overrounds = list(df_merge_col.columns.values)[1:3]
plt.figure(figsize=(12,7))
for overround in overrounds:
sns.distplot(df_merge_col[overround].astype('float'))
plt.title('Distribution of Market Overrounds (Bookies v Betfair Starting Prices)', size = 22)
plt.xlabel('Overround %', size = 16)
plt.legend(labels = overrounds, loc = 'upper left', prop={'size': 14} )
plt.show()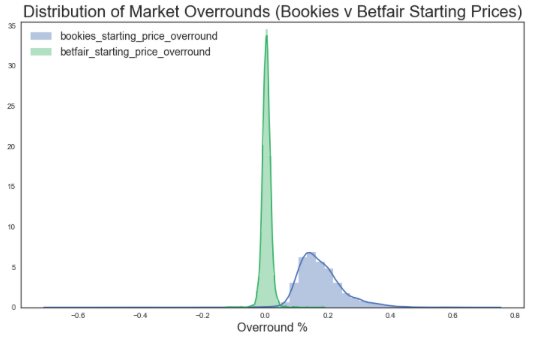
print('Average (mean) overround for bookies starting prices : ', df_merge_col['bookies_starting_price_overround'].mean())
Average (mean) overround for bookies starting prices : 0.17552602236487852print('Average (mean) overround for Betfair starting prices : ', df_merge_col['betfair_starting_price_overround'].mean())
Average (mean) overround for betfair starting prices : 0.0035572168150755853from scipy import stats
stats.ttest_ind(df_merge_col['bookies_starting_price_overround'].astype('float'), df_merge_col['betfair_starting_price_overround'].astype('float'))
Ttest_indResult(statistic=152.77780026940124, pvalue=0.0)This T-test result (p-value = 0.0) confirms that there is a statistical difference between the means of each sample i.e. there is a difference between the averages of bookmaker and exchange starting prices
As shown above, bookie’s had a much greater overround (for starting prices) of approximately 17% compared to Betfair’s 0%. This reflects a large difference in value between the two betting mediums, reflecting that you are likely to find much better odds through betting on Betfair than with bookmakers, and to do so just before post time (in the large majority of cases).
Further analysis could look into if these findings holds true for all price ranges (and if the same results are found across different market types, not just a sample of data from 2018 flat races).
Querying From Smartform Using Python
By Tom Bardrick on Friday, April 26th, 2019Python is now one of the most commonly used programming languages – at the time of writing 4th in popularity according to the TIOBE index. It’s also a popular choice for data manipulation and data science, with plenty of packages such as Pandas for preparing data and Scikit-learn for machine learning meaning that – like R – it can be an ideal environment to use for analysing horseracing data and building prediction models. Here, we discuss first steps to start using Python with Smartform (the MySQL horseracing database from Betwise) in order to connect to the database, run queries, and start using the data within the Python environment.
Installing ‘PyMySQL’
In order to query into a MySQL database directly from Python, the PyMySQL package needs to be installed. More can be read about the package requirements here:
This needs to be done outside of the IPython Shell using the ‘pip’ command. In a command prompt (if using Windows) or bash prompt (if using macOS) use
$ pip install pymysql More information on how to install packages for python can be found here:
Importing ‘PyMySQL’
After doing so, the pymysql package then needs to be imported into the IPython Shell, by running the following code:
import pymysqlNow you have the necessary package installed to make contact between Python and the MySQL database.
Establishing a Connection
In order to connect the IPython Shell to the MySQL database you will need to know your MySQL database credentials. These details would have been inputted by the user when creating the MySQL database.
These following details are: host name, user name, password and database name (e.g. ‘smartform’). These details need to be inputted into the strings below.
Note: The password has been filled with asterisks for security reasons but do enter your actual password here
# Inputting database credentials
connection = pymysql.connect(host='localhost', user='root', passwd ='********', database = 'smartform') If all of the credentials are correct, the connection should be established and the code should run without an error message. If for whatever reason this code doesn’t work, make sure you have entered the correct details and you have imported the ‘pymysql’ package correctly.
Creating a Cursor
To be able to make queries from the MySQL database, a cursor needs to be created. The cursor is effectively a control structure that enables traversal over the records in a database. This can be done by simply running the following code.
cursor = connection.cursor()Making a Query
Write out your desired query as a string, as you would normally write out a SQL query.
The following query is an example of how to return all of the unique runners (and their associated runner names) with an OR > 160 and then order the runners’ names alphabetically.
query = '''SELECT DISTINCT runner_id, name
FROM historic_runners
WHERE official_rating > 160
ORDER BY name ASC
''' Then call this query into the ‘cursor.execute’ function (this will return the number of records in the query as an output).
cursor.execute(query)Then use ‘cursor.fetchall()’ to retrieve all of the data entries corresponding to this query, calling it into a variable.
rows = cursor.fetchall()Use a ‘for loop’ to print and inspect the query output.
for row in rows[:10]:
print(row)(514205, 'Afsoun')
(2048799, 'Agrapart')
(1435705, 'Al Ferof')
(547061, 'Albertas Run')
(1692968, 'Alelchi Inois')
(160435, 'Alexander Banquet')
(229855, 'Allegedly Red')
(2037368, 'Altior')
(447515, 'Andreas')
(2104005, 'Anibale Fly')Plotting Trainer, Jockey and Sire Statistics in a Stacked Bar Chart with R
By Phill Clarke on Saturday, June 23rd, 2018Earlier in the week we looked at how to use a for loop to iterate across rows of a dataframe to calculate statistics in an automated manner. Interesting and useful, but we only looked at one specific set of circumstance; trainer and jockey combinations in Group races. There are many other useful statistics which can be used to examine a race. This article focuses on today’s Diamond Jubilee Stakes at Royal Ascot, extends the one collection of statistics to four and finally plots the outcome in a visual format.
As the code examples for this article now extend to beyond 550 lines, it is not practicle to include all the code in-line with the article text. Therefore, only certain examples will be included in-line with the full R code will be provided at the end of the article.
The initial assumption is that data has been returned from the Smartform database, although some additional field are now returned, specifically trainer_id, jockey_id and sire_name.
# Select relevant historic results
sql1 <- paste("SELECT historic_races.course,
historic_races.meeting_date,
historic_races.conditions,
historic_races.group_race,
historic_races.race_type_id,
historic_races.race_type,
historic_races.distance_yards,
historic_runners.name,
historic_runners.jockey_name,
historic_runners.trainer_name,
historic_runners.finish_position,
historic_runners.starting_price_decimal,
historic_runners.trainer_id,
historic_runners.jockey_id,
historic_runners.sire_name
FROM smartform.historic_runners
JOIN smartform.historic_races USING (race_id)
WHERE historic_races.meeting_date >= '2012-01-01'", sep="")
Previously we created a trainer & jockey function to investigate these specific combinations in Group races. This is now extended to just trainer, just jockey and just sire functions. The trainer function is found below.
# Trainer stats
# Name the function and add some arguments
tr <- function(race_filter = "", price_filter = 1000, trainer){
# Filter for flat races only
flat_races_only <- dplyr::filter(smartform_results,
race_type_id == 12 |
race_type_id == 15)
# Add an if else statement for the race_filter argument
if (race_filter == "group"){
filtered_races <- dplyr::filter(flat_races_only,
group_race == 1 |
group_race == 2 |
group_race == 3 )
} else {
filtered_races = flat_races_only
}
# Filter by trainer id
trainer_filtered <- dplyr::filter(filtered_races,
grepl(trainer, trainer_id))
# Filter by price
trainer_price_filtered <- dplyr::filter(trainer_filtered,
starting_price_decimal <= price_filter)
# Calculate Profit and Loss
trainer_cumulative <- cumsum(
ifelse(trainer_price_filtered$finish_position == 1,
(trainer_price_filtered$starting_price_decimal-1),
-1)
)
# Calculate Strike Rate
winners <- nrow(dplyr::filter(trainer_price_filtered,
finish_position == 1))
runners <- nrow(trainer_price_filtered)
strike_rate <- (winners / runners) * 100
# Calculate Profit on Turnover or Yield
profit_on_turnover <- (tail(trainer_cumulative, n=1) / runners) * 100
# Check if POT is zero length to catch later errors
if (length(profit_on_turnover) == 0) profit_on_turnover <- 0
# Calculate Impact Values
# First filter all runners by price, to return those just starting at the price_filter or less
all_runners <- nrow(dplyr::filter(filtered_races,
starting_price_decimal <= price_filter))
# Filter all winners by the price filter
all_winners <- nrow(dplyr::filter(filtered_races,
finish_position == 1 &
starting_price_decimal <= price_filter))
# Now calculate the Impact Value
iv <- (winners / all_winners) / (runners / all_runners)
# Calculate Actual vs Expected ratio
# # Convert all decimal odds to probabilities
total_sp <- sum(1/trainer_price_filtered$starting_price_decimal)
# Calculate A/E by dividing the number of winners, by the sum of all SP probabilities.
ae <- winners / total_sp
# Calculate Archie
archie <- (runners * (winners - total_sp)^2)/ (total_sp * (runners - total_sp))
# Calculate the Confidence figure
conf <- pchisq(archie, df = 1)*100
# Create an empty variable
trainer <- NULL
# Add all calculated figures as named objects to the variable, which creates a list
trainer$tr_runners <- runners
trainer$tr_winners <- winners
trainer$tr_sr <- strike_rate
trainer$tr_pot <- profit_on_turnover
trainer$tr_iv <- iv
trainer$tr_ae <- ae
trainer$tr_conf <- conf
# Add an error check to convert all NaN values to zero
final_results <- unlist(trainer)
final_results[ is.nan(final_results) ] <- 0
# Manipulate the layout of returned results to be a nice dataframe
final_results <- t(as.data.frame(final_results))
rownames(final_results) <- c()
# 2 decimal places only
round(final_results, 2)
# Finally, close the function
}
Note that in the above code, instead of filtering by trainer_name, we are now filtering by trainer_id. This is due to the fact that sometimes the trainer names in the daily racing data do not exactly match those in the historic data. For example, Sir Michael Stoute hasn’t always been a knight. Therefore, if we were just matching on trainer_name there would be some occassions where this fails and no results are returned. Smartform instead provides a unique identification number for trainers and jockeys, which insures there will always be a match between historic and daily data.
The function above is just one example. In order to produce the charts later in this article, additional jockey and sire functions have been added, bringing the total to four; trainer, jockey, trainer & jockey and sire. The number of statistics could be extended much further to include angles such as trainer & distance, trainer & course, trainer & age (2yo, 3yo, 4yo+ races) and many more.
The for loop also now includes all four of these functions.
# Create placeholder lists which will be required later
row_tr <- list()
row_jc <- list()
row_tj <- list()
row_sr <- list()
# Setup the loop
# For each horse in the group_races_only dataframe
for (i in group_races_only$name) {
runner_details = group_races_only[group_races_only$name==i,]
# Extract trainer, jockey id and sire names
trainer <- runner_details$trainer_id
jockey <- runner_details$jockey_id
sire <- runner_details$sire_name
# Apply the Trainer function for Group races only
trainer_combo <- tr(race_filter = "group",
trainer = trainer)
# Add results row by row to the previously defined list
row_tr[[i]] <- trainer_combo
# Apply the Jockey function for Group races only
jockey_combo <- jc(race_filter = "group",
jockey = jockey)
# Add results row by row to the previously defined list
row_jc[[i]] <- jockey_combo
# Apply the Trainer/Jockey function for Group races only
trainer_jockey_combo <- tj(race_filter = "group",
trainer = trainer, jockey = jockey)
# Add results row by row to the previously defined list
row_tj[[i]] <- trainer_jockey_combo
# Apply the Sire function for Group races only
sire_combo <- sr(race_filter = "group",
sire = sire)
# Add results row by row to the previously defined list
row_sr[[i]] <- sire_combo
# Create a final dataframe
stats_final_tr <- as.data.frame(do.call("rbind", row_tr))
stats_final_jc <- as.data.frame(do.call("rbind", row_jc))
stats_final_tj <- as.data.frame(do.call("rbind", row_tj))
stats_final_sr <- as.data.frame(do.call("rbind", row_sr))
}
# Create a new variable called racecard. Bind together the generic race details with the newly created stats
racecard <- cbind(group_races_only,stats_final_tr)
racecard <- cbind(racecard,stats_final_jc)
racecard <- cbind(racecard,stats_final_tj)
racecard <- cbind(racecard,stats_final_sr)
Viewing the final racecard now shows forty columns and a wall of data. This isn’t perhaps the easiest way to visualise the overall picture. Instead, we’ll create a stacked barchart showing Impact Values for all four angles. The legend shows tr_iv, jc_iv, tj_iv and sr_iv for the trainer, jockey, trainer & jockey and sire impact values.
# Filter for Diamond Jubilee Only
diamond_jubilee <- dplyr::filter(racecard,
grepl("Diamond Jubilee",
race_title))
# Filter for just the IV columns which we will plot
racecard_filtered_iv <- diamond_jubilee[,c("name","tr_iv","jc_iv", "tj_iv", "sr_iv")]
# Convert the racecard from wide to long format
racecard_long_iv <- melt(racecard_filtered_iv, id.var="name")
# Plot a stacked barchart
ggplot(racecard_long_iv, aes(x = name, y = value, fill = variable)) +
geom_bar(stat = "identity") +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
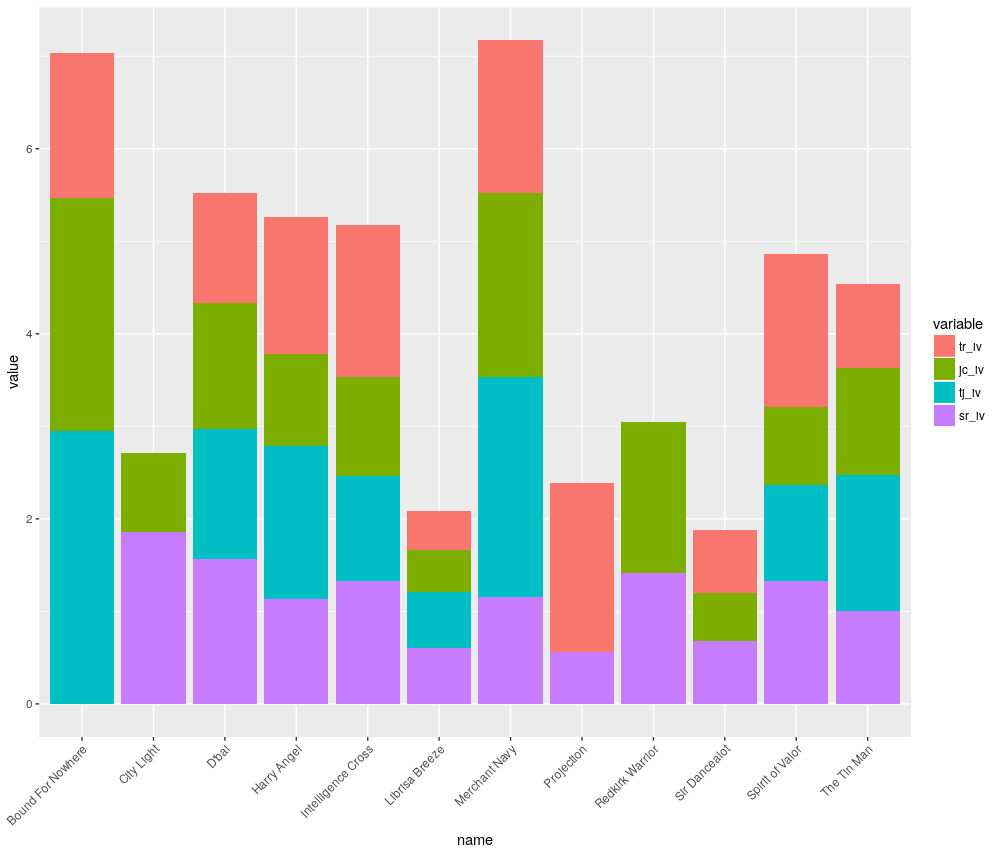
The highest bars indicate the highest cumulative Impact Values. Some bars do not include all four factors, as sometimes there were no results returned. For example, Bound For Nowhere’s sire, The Factor, has only had one Group runner in the UK & Ireland, which did not win. Therefore, there is no data to calculate strike rate, impact value etc.
This means one needs to be careful examining the chart and also take time to ponder the data in the dataframe. Some sample sizes may be very small and a question should be asked if they are statistically relevant. Bound For Nowhere’s Trainer & Jockey Impact Value is the highest in the race, but this is from only six runners. Compared to Merchant Navy with the second highest tj_iv, but from 357 runners.
Nonetheless, a visual method like this can still assist to narrow the field. Harry Angel, the favourite for the race, is certainly not a standout in the chart, with decent sample sizes across all four factors.
The stacked barchart can also be applied to Actual vs Expected figures, strike rates or Confidence figures. The chart below displays stacked A/E for a more value oriented view.
# Filter for just the AE columns which we will plot
racecard_filtered_ae <- diamond_jubilee[,c("name","tr_ae","jc_ae", "tj_ae", "sr_ae")]
# Convert the racecard from wide to long format
racecard_long_ae <- melt(racecard_filtered_ae, id.var="name")
# Plot a stacked barchart
ggplot(racecard_long_ae, aes(x = name, y = value, fill = variable)) +
geom_bar(stat = "identity") +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
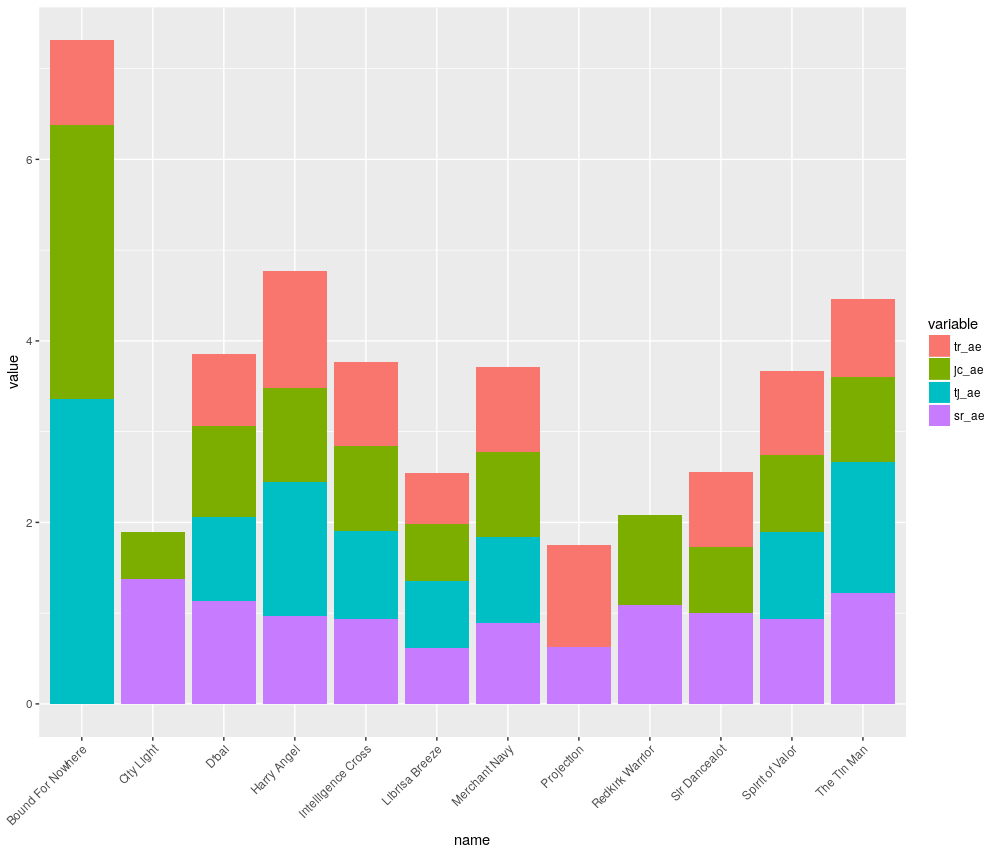
Once again, keep Bound for Nowhere’s small sample sizes in mind. Harry Angel appears to be a better betting proposition based on this chart.
Another way to look at this data might be as a grouped bar chart, where the IV and A/E figures are plotted for each horse next to each other.
# Filter for just the AE columns which we will plot
racecard_filtered_all <- diamond_jubilee[,c("name","tr_iv","jc_iv", "tj_iv", "sr_iv",
"tr_ae","jc_ae", "tj_ae", "sr_ae")]
# Convert the racecard from wide to long format
racecard_long_all <- melt(racecard_filtered_all, id.var="name")
# Plot a grouped barchart
ggplot(racecard_long_all, aes(x = name, y = value, fill = variable)) +
geom_bar(position = "dodge", stat="identity") +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
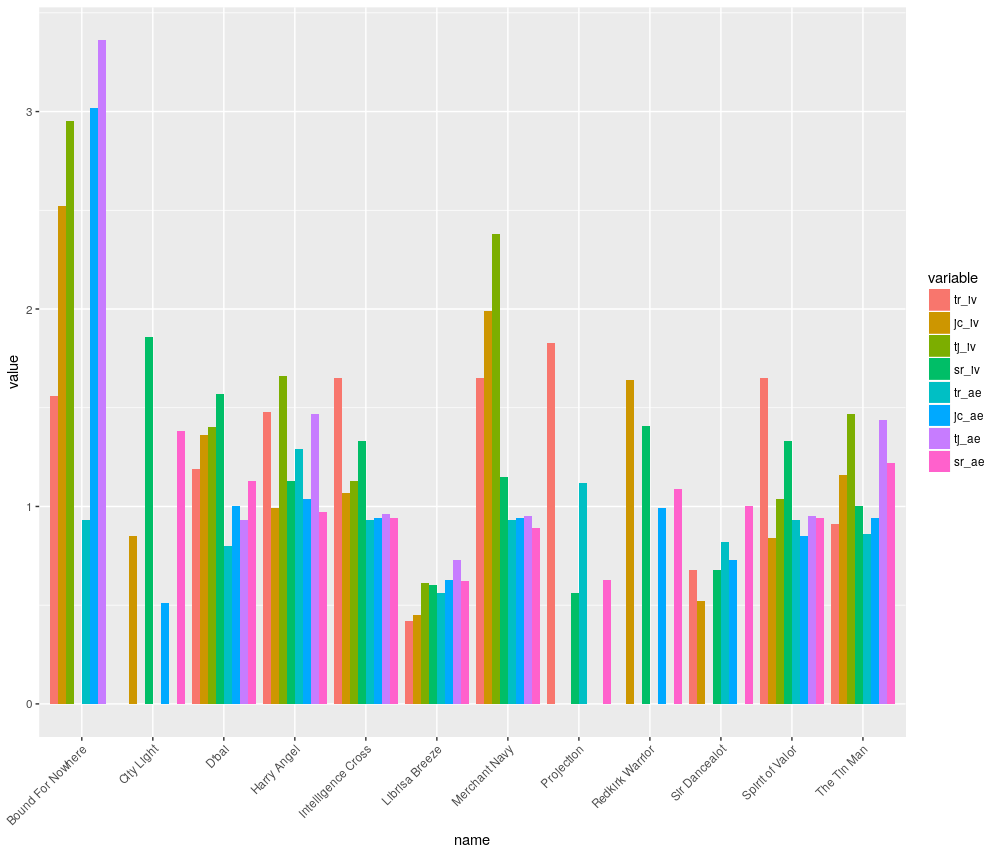
Although Sire IV is missing for Bound for Nowhere, his other figures do all point to a superier trainer and jockey, albeit from small sample size. How to statistically deal with these small sample sizes will be covered in a future article on Bayesian techniques.
Which horses might be included in a shortlist for today’s Diamond Jubilee? Even with small sample sizes, but knowing Wesley Ward’s Ascot success with sprinters, it may be wise to include Bound for Nowhere, who is currently 14.0 on Betfair. Merchant Navy (IV) and Harry Angel (A/E) are both positives, although much shorter priced at the top of the market.
It is important not to just rely on the data. There are many different factors to consider and a good knowledge of general form is also required. Therefore, after all that work, one might still decide just to back the Aussie danger and triple Group 1 sprint winner, Redkirk Warrior.
Good luck!
Questions and queries about this article should be posted as a comment below or on the Betwise Q&A board.
The full R code used in this article is found below.
# Load the library packages
library("RMySQL")
library("dplyr")
library("reshape2")
library("ggplot2")
# Connect to the Smartform database. Substitute the placeholder credentials for your own.
# The IP address can be substituted for a remote location if appropriate.
con <- dbConnect(MySQL(),
host='127.0.0.1',
user='yourusername',
password='yourpassword',
dbname='smartform')
# Select relevant historic results
sql1 <- paste("SELECT historic_races.course,
historic_races.meeting_date,
historic_races.conditions,
historic_races.group_race,
historic_races.race_type_id,
historic_races.race_type,
historic_races.distance_yards,
historic_runners.name,
historic_runners.jockey_name,
historic_runners.trainer_name,
historic_runners.finish_position,
historic_runners.starting_price_decimal,
historic_runners.trainer_id,
historic_runners.jockey_id,
historic_runners.sire_name
FROM smartform.historic_runners
JOIN smartform.historic_races USING (race_id)
WHERE historic_races.meeting_date >= '2012-01-01'", sep="")
smartform_results <- dbGetQuery(con, sql1)
# Remove non-runners and non-finishers
smartform_results <- dplyr::filter(smartform_results, !is.na(finish_position))
# Select relevant daily results for tomorrow
sql2 <- paste("SELECT daily_races.course,
daily_races.race_title,
daily_races.meeting_date,
daily_races.distance_yards,
daily_runners.cloth_number,
daily_runners.name,
daily_runners.trainer_name,
daily_runners.jockey_name,
daily_runners.sire_name,
daily_runners.forecast_price_decimal,
daily_runners.trainer_id,
daily_runners.jockey_id
FROM smartform.daily_races
JOIN smartform.daily_runners USING (race_id)
WHERE daily_races.meeting_date >='2018-06-23'", sep="")
smartform_daily_results <- dbGetQuery(con, sql2)
dbDisconnect(con)
# Remove non-runners
smartform_daily_results <- dplyr::filter(smartform_daily_results, !is.na(forecast_price_decimal))
# Trainer stats
# Name the function and add some arguments
tr <- function(race_filter = "", price_filter = 1000, trainer){
# Filter for flat races only
flat_races_only <- dplyr::filter(smartform_results,
race_type_id == 12 |
race_type_id == 15)
# Add an if else statement for the race_filter argument
if (race_filter == "group"){
filtered_races <- dplyr::filter(flat_races_only,
group_race == 1 |
group_race == 2 |
group_race == 3 )
} else {
filtered_races = flat_races_only
}
# Filter by trainer name
trainer_filtered <- dplyr::filter(filtered_races,
grepl(trainer, trainer_id))
# Filter by price
trainer_price_filtered <- dplyr::filter(trainer_filtered,
starting_price_decimal <= price_filter)
# Calculate Profit and Loss
trainer_cumulative <- cumsum(
ifelse(trainer_price_filtered$finish_position == 1,
(trainer_price_filtered$starting_price_decimal-1),
-1)
)
# Calculate Strike Rate
winners <- nrow(dplyr::filter(trainer_price_filtered,
finish_position == 1))
runners <- nrow(trainer_price_filtered)
strike_rate <- (winners / runners) * 100
# Calculate Profit on Turnover or Yield
profit_on_turnover <- (tail(trainer_cumulative, n=1) / runners) * 100
# Check if POT is zero length to catch later errors
if (length(profit_on_turnover) == 0) profit_on_turnover <- 0
# Calculate Impact Values
# First filter all runners by price, to return those just starting at the price_filter or less
all_runners <- nrow(dplyr::filter(filtered_races,
starting_price_decimal <= price_filter))
# Filter all winners by the price filter
all_winners <- nrow(dplyr::filter(filtered_races,
finish_position == 1 &
starting_price_decimal <= price_filter))
# Now calculate the Impact Value
iv <- (winners / all_winners) / (runners / all_runners)
# Calculate Actual vs Expected ratio
# # Convert all decimal odds to probabilities
total_sp <- sum(1/trainer_price_filtered$starting_price_decimal)
# Calculate A/E by dividing the number of winners, by the sum of all SP probabilities.
ae <- winners / total_sp
# Calculate Archie
archie <- (runners * (winners - total_sp)^2)/ (total_sp * (runners - total_sp))
# Calculate the Confidence figure
conf <- pchisq(archie, df = 1)*100
# Create an empty variable
trainer <- NULL
# Add all calculated figures as named objects to the variable, which creates a list
trainer$tr_runners <- runners
trainer$tr_winners <- winners
trainer$tr_sr <- strike_rate
trainer$tr_pot <- profit_on_turnover
trainer$tr_iv <- iv
trainer$tr_ae <- ae
trainer$tr_conf <- conf
# Add an error check to convert all NaN values to zero
final_results <- unlist(trainer)
final_results[ is.nan(final_results) ] <- 0
# Manipulate the layout of returned results to be a nice dataframe
final_results <- t(as.data.frame(final_results))
rownames(final_results) <- c()
# 2 decimal places only
round(final_results, 2)
# Finally, close the function
}
# Jockey stats
# Name the function and add some arguments
jc <- function(race_filter = "", price_filter = 1000, jockey){
# Filter for flat races only
flat_races_only <- dplyr::filter(smartform_results,
race_type_id == 12 |
race_type_id == 15)
# Add an if else statement for the race_filter argument
if (race_filter == "group"){
filtered_races <- dplyr::filter(flat_races_only,
group_race == 1 |
group_race == 2 |
group_race == 3 )
} else {
filtered_races = flat_races_only
}
# Filter by trainer name
jockey_filtered <- dplyr::filter(filtered_races,
grepl(jockey, jockey_id))
# Filter by price
jockey_price_filtered <- dplyr::filter(jockey_filtered,
starting_price_decimal <= price_filter)
# Calculate Profit and Loss
jockey_cumulative <- cumsum(
ifelse(jockey_price_filtered$finish_position == 1,
(jockey_price_filtered$starting_price_decimal-1),
-1)
)
# Calculate Strike Rate
winners <- nrow(dplyr::filter(jockey_price_filtered,
finish_position == 1))
runners <- nrow(jockey_price_filtered)
strike_rate <- (winners / runners) * 100
# Calculate Profit on Turnover or Yield
profit_on_turnover <- (tail(jockey_cumulative, n=1) / runners) * 100
# Check if POT is zero length to catch later errors
if (length(profit_on_turnover) == 0) profit_on_turnover <- 0
# Calculate Impact Values
# First filter all runners by price, to return those just starting at the price_filter or less
all_runners <- nrow(dplyr::filter(filtered_races,
starting_price_decimal <= price_filter))
# Filter all winners by the price filter
all_winners <- nrow(dplyr::filter(filtered_races,
finish_position == 1 &
starting_price_decimal <= price_filter))
# Now calculate the Impact Value
iv <- (winners / all_winners) / (runners / all_runners)
# Calculate Actual vs Expected ratio
# # Convert all decimal odds to probabilities
total_sp <- sum(1/jockey_price_filtered$starting_price_decimal)
# Calculate A/E by dividing the number of winners, by the sum of all SP probabilities.
ae <- winners / total_sp
# Calculate Archie
archie <- (runners * (winners - total_sp)^2)/ (total_sp * (runners - total_sp))
# Calculate the Confidence figure
conf <- pchisq(archie, df = 1)*100
# Create an empty variable
jockey <- NULL
# Add all calculated figures as named objects to the variable, which creates a list
jockey$jc_runners <- runners
jockey$jc_winners <- winners
jockey$jc_sr <- strike_rate
jockey$jc_pot <- profit_on_turnover
jockey$jc_iv <- iv
jockey$jc_ae <- ae
jockey$jc_conf <- conf
# Add an error check to convert all NaN values to zero
final_results <- unlist(jockey)
final_results[ is.nan(final_results) ] <- 0
# Manipulate the layout of returned results to be a nice dataframe
final_results <- t(as.data.frame(final_results))
rownames(final_results) <- c()
# 2 decimal places only
round(final_results, 2)
# Finally, close the function
}
# Trainer and Jockey stats
# Name the function and add some arguments
tj <- function(race_filter = "", price_filter = 1000, trainer, jockey){
# Filter for flat races only
flat_races_only <- dplyr::filter(smartform_results,
race_type_id == 12 |
race_type_id == 15)
# Add an if else statement for the race_filter argument
if (race_filter == "group"){
filtered_races <- dplyr::filter(flat_races_only,
group_race == 1 |
group_race == 2 |
group_race == 3 )
} else {
filtered_races = flat_races_only
}
# Filter by trainer name
trainer_filtered <- dplyr::filter(filtered_races,
grepl(trainer, trainer_id))
# Remove non-runners
# trainer_name_filtered <- dplyr::filter(trainer_filtered, !is.na(finish_position))
# Filter by jockey name
trainer_jockey_filtered <- dplyr::filter(trainer_filtered,
grepl(jockey, jockey_id))
# Filter by price
trainer_jockey_price_filtered <- dplyr::filter(trainer_jockey_filtered,
starting_price_decimal <= price_filter)
# Calculate Profit and Loss
trainer_jockey_cumulative <- cumsum(
ifelse(trainer_jockey_price_filtered$finish_position == 1,
(trainer_jockey_price_filtered$starting_price_decimal-1),
-1)
)
# Calculate Strike Rate
winners <- nrow(dplyr::filter(trainer_jockey_price_filtered,
finish_position == 1))
runners <- nrow(trainer_jockey_price_filtered)
strike_rate <- (winners / runners) * 100
# Calculate Profit on Turnover or Yield
profit_on_turnover <- (tail(trainer_jockey_cumulative, n=1) / runners) * 100
# Check if POT is zero length to catch later errors
if (length(profit_on_turnover) == 0) profit_on_turnover <- 0
# Calculate Impact Values
# First filter all runners by price, to return those just starting at the price_filter or less
all_runners <- nrow(dplyr::filter(filtered_races,
starting_price_decimal <= price_filter))
# Filter all winners by the price filter
all_winners <- nrow(dplyr::filter(filtered_races,
finish_position == 1 &
starting_price_decimal <= price_filter))
# Now calculate the Impact Value
iv <- (winners / all_winners) / (runners / all_runners)
# Calculate Actual vs Expected ratio
# # Convert all decimal odds to probabilities
total_sp <- sum(1/trainer_jockey_price_filtered$starting_price_decimal)
# Calculate A/E by dividing the number of winners, by the sum of all SP probabilities.
ae <- winners / total_sp
# Calculate Archie
archie <- (runners * (winners - total_sp)^2)/ (total_sp * (runners - total_sp))
# Calculate the Confidence figure
conf <- pchisq(archie, df = 1)*100
# Create an empty variable
trainer_jockey <- NULL
# Add all calculated figures as named objects to the variable, which creates a list
trainer_jockey$tj_runners <- runners
trainer_jockey$tj_winners <- winners
trainer_jockey$tj_sr <- strike_rate
trainer_jockey$tj_pot <- profit_on_turnover
trainer_jockey$tj_iv <- iv
trainer_jockey$tj_ae <- ae
trainer_jockey$tj_conf <- conf
# Add an error check to convert all NaN values to zero
final_results <- unlist(trainer_jockey)
final_results[ is.nan(final_results) ] <- 0
# Manipulate the layout of returned results to be a nice dataframe
final_results <- t(as.data.frame(final_results))
rownames(final_results) <- c()
# 2 decimal places only
round(final_results, 2)
# Finally, close the function
}
# Sire stats
# Name the function and add some arguments
sr <- function(race_filter = "", price_filter = 1000, sire){
# Filter for flat races only
flat_races_only <- dplyr::filter(smartform_results,
race_type_id == 12 |
race_type_id == 15)
# Add an if else statement for the race_filter argument
if (race_filter == "group"){
filtered_races <- dplyr::filter(flat_races_only,
group_race == 1 |
group_race == 2 |
group_race == 3 )
} else {
filtered_races = flat_races_only
}
# Filter by trainer name
sire_filtered <- dplyr::filter(filtered_races,
grepl(sire, sire_name))
# Filter by price
sire_price_filtered <- dplyr::filter(sire_filtered,
starting_price_decimal <= price_filter)
# Calculate Profit and Loss
sire_cumulative <- cumsum(
ifelse(sire_price_filtered$finish_position == 1,
(sire_price_filtered$starting_price_decimal-1),
-1)
)
# Calculate Strike Rate
winners <- nrow(dplyr::filter(sire_price_filtered,
finish_position == 1))
runners <- nrow(sire_price_filtered)
strike_rate <- (winners / runners) * 100
# Calculate Profit on Turnover or Yield
profit_on_turnover <- (tail(sire_cumulative, n=1) / runners) * 100
# Check if POT is zero length to catch later errors
if (length(profit_on_turnover) == 0) profit_on_turnover <- 0
# Calculate Impact Values
# First filter all runners by price, to return those just starting at the price_filter or less
all_runners <- nrow(dplyr::filter(filtered_races,
starting_price_decimal <= price_filter))
# Filter all winners by the price filter
all_winners <- nrow(dplyr::filter(filtered_races,
finish_position == 1 &
starting_price_decimal <= price_filter))
# Now calculate the Impact Value
iv <- (winners / all_winners) / (runners / all_runners)
# Calculate Actual vs Expected ratio
# # Convert all decimal odds to probabilities
total_sp <- sum(1/sire_price_filtered$starting_price_decimal)
# Calculate A/E by dividing the number of winners, by the sum of all SP probabilities.
ae <- winners / total_sp
# Calculate Archie
archie <- (runners * (winners - total_sp)^2)/ (total_sp * (runners - total_sp))
# Calculate the Confidence figure
conf <- pchisq(archie, df = 1)*100
# Create an empty variable
sire <- NULL
# Add all calculated figures as named objects to the variable, which creates a list
sire$sr_runners <- runners
sire$sr_winners <- winners
sire$sr_sr <- strike_rate
sire$sr_pot <- profit_on_turnover
sire$sr_iv <- iv
sire$sr_ae <- ae
sire$sr_conf <- conf
# Add an error check to convert all NaN values to zero
final_results <- unlist(sire)
final_results[ is.nan(final_results) ] <- 0
# Manipulate the layout of returned results to be a nice dataframe
final_results <- t(as.data.frame(final_results))
rownames(final_results) <- c()
# 2 decimal places only
round(final_results, 2)
# Finally, close the function
}
# Filter tomorrow's races for Group races only
group_races_only <- dplyr::filter(smartform_daily_results,
grepl(paste(c("Group 1", "Group 2", "Group 3"), collapse="|"), race_title))
# Create placeholder lists which will be required later
row_tr <- list()
row_jc <- list()
row_tj <- list()
row_sr <- list()
# Setup the loop
# For each horse in the group_races_only dataframe
for (i in group_races_only$name) {
runner_details = group_races_only[group_races_only$name==i,]
# Extract trainer and jockey names
trainer <- runner_details$trainer_id
jockey <- runner_details$jockey_id
sire <- runner_details$sire_name
# Apply the Trainer function for Group races only
trainer_combo <- tr(race_filter = "group",
trainer = trainer)
# Add results row by row to the previously defined list
row_tr[[i]] <- trainer_combo
# Apply the Jockey function for Group races only
jockey_combo <- jc(race_filter = "group",
jockey = jockey)
# Add results row by row to the previously defined list
row_jc[[i]] <- jockey_combo
# Apply the Trainer/Jockey function for Group races only
trainer_jockey_combo <- tj(race_filter = "group",
trainer = trainer, jockey = jockey)
# Add results row by row to the previously defined list
row_tj[[i]] <- trainer_jockey_combo
# Apply the Sire function for Group races only
sire_combo <- sr(race_filter = "group",
sire = sire)
# Add results row by row to the previously defined list
row_sr[[i]] <- sire_combo
# Create a final dataframe
stats_final_tr <- as.data.frame(do.call("rbind", row_tr))
stats_final_jc <- as.data.frame(do.call("rbind", row_jc))
stats_final_tj <- as.data.frame(do.call("rbind", row_tj))
stats_final_sr <- as.data.frame(do.call("rbind", row_sr))
}
# Create a new variable called racecard. Bind together the generic race details with the newly created stats
racecard <- cbind(group_races_only,stats_final_tr)
racecard <- cbind(racecard,stats_final_jc)
racecard <- cbind(racecard,stats_final_tj)
racecard <- cbind(racecard,stats_final_sr)
# Filter for Diamond Jubilee Only
diamond_jubilee <- dplyr::filter(racecard,
grepl("Diamond Jubilee",
race_title))
# Filter for just the IV columns which we will plot
racecard_filtered_iv <- diamond_jubilee[,c("name","tr_iv","jc_iv", "tj_iv", "sr_iv")]
# Convert the racecard from wide to long format
racecard_long_iv <- melt(racecard_filtered_iv, id.var="name")
# Plot a stacked barchart
ggplot(racecard_long_iv, aes(x = name, y = value, fill = variable)) +
geom_bar(stat = "identity") +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
# Filter for just the AE columns which we will plot
racecard_filtered_ae <- diamond_jubilee[,c("name","tr_ae","jc_ae", "tj_ae", "sr_ae")]
# Convert the racecard from wide to long format
racecard_long_ae <- melt(racecard_filtered_ae, id.var="name")
# Plot a stacked barchart
ggplot(racecard_long_ae, aes(x = name, y = value, fill = variable)) +
geom_bar(stat = "identity") +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
# Filter for just the AE columns which we will plot
racecard_filtered_all <- diamond_jubilee[,c("name","tr_iv","jc_iv", "tj_iv", "sr_iv",
"tr_ae","jc_ae", "tj_ae", "sr_ae")]
# Convert the racecard from wide to long format
racecard_long_all <- melt(racecard_filtered_all, id.var="name")
# Plot a grouped barchart
ggplot(racecard_long_all, aes(x = name, y = value, fill = variable)) +
geom_bar(position = "dodge", stat="identity") +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
2 year old sire stats for Royal Ascot
By Nick Franks on Thursday, June 21st, 2018Two year old races at Royal Ascot are some of the most exciting out there, but trying to find a winner based on their racing form alone is a difficult, if not impossible, task.
Why is this? At this stage of the season, most contenders have only had one, two or three runs; most of the form is from diverse courses in varying classes on different ground, with different form lines, and to cap it all the fields are typically large. Needles and haystacks spring to mind. Trainer strike rates can be useful, as we’ve covered in recent posts, as can their records for Royal Ascot in particular, but still don’t tell us much about the horse’s ability itself.
Fortunately there’s more than one way to look at assessing form and future potential, and it’s at times when runners’ form is unexposed that it generally pays to look at other factors in the horse’s profile as indicators of potential ability – especially when there is far more information available than the bare runs – such as the form of the horse’s sire.
This can be a particularly strong pointer at Royal Ascot and allows us, by a different means other than runner form alone, to use a powerful new angle for establishing the potential of the animal in question.
Today we’re going to look at measuring sire strike rates and ranking them, a method which has been doing quite well so far this Royal Ascot. Of the two 2 year old races so far, on Tuesday, the top contender by sire strike rate sire produced the winner of the Coventry Stakes in Calyx at 2/1.
Here’s a screenshot of the query results for the Coventry:
![]()
Yesterday, Wednesday, saw the joint top sire strike rate produce the second in Gossamer Wings at 25/1, and the fourth, So Perfect, at 8/1. Another screenshot of the query follows:
![]()
Sod’s law says that today will be the day that the two year old sires system fails, since that happens all the time in betting – and of course there is no such thing as a sure thing. But there is such a thing as gaining an “an edge” with a method or a combination of methods. The edge needs to be measured and weighed up against the prices on offer to see if there is value, but that’s not what today’s post is about – it’s about a method to generate a possible edge in the first place.
We can also pick holes in ranking anything by strike rate. The winner on day 1 included its own previous win in the very small sample size – because, as a sire, Kingman’s progency have not yet had many runs.
But given those warnings, there is usually little influence of the horse itself in this method, particularly when there is a large sample of previous runs. Also, on the question of sample size, it’s possible to overcome the problem of small samples by applying some simple Bayesian priors to augment the winner and runner ratios – but more about that as well on another day.
So without further ado, here is today’s ranking of horses by sire strike rate for the Norfolk Stakes. Only 10 runners, so not such a cavalry charge as the first two days, and also note very narrow variance between strike rates, with a low strike rate at 11%, as top.

And – since it’s better to teach a man to fish, here is the Smartform query that subscribers can run for themselves for the rest of Royal Ascot.
-- Select the flat turf races for 2yos today at Ascot with selected columns from the daily races and runers tables
-- Note Database lists the course as Royal_Ascot so looking for all races with Ascot in the course hense using like with %
DROP TABLE IF EXISTS today_2yoturf_races;
CREATE TABLE today_2yoturf_races AS (
select
race_id, meeting_date, scheduled_time, Course, cloth_number, name, foaling_date, sire_name ,
forecast_price_decimal, Trainer_Name Trainer, Jockey_Name Jockey, Stall_Number Draw
from daily_races
join daily_runners using (race_id)
where meeting_date > curdate()
and race_type = 'flat'
and track_type = 'turf'
and age_range = '2YO only'
and course like '%Ascot%' );
-- Create history for 2yo turf sires
--
DROP TABLE IF EXISTS hist_2yoturf_sires;
CREATE TABLE hist_2yoturf_sires AS (
select z.sire_name ,
COUNT(*) AS Runners,
SUM(winner) AS Winners,
sum(WinProfit) as WinProfit,
ROUND(((SUM(CASE WHEN z.finish_position = 1 THEN 1 ELSE 0 END) / COUNT(*)) * 100),2) AS WinPct,
case when SUM(winner) = 0 then NULL else
round((SUM(CASE WHEN z.winner = 1 THEN z.distance_yards ELSE 0 END)/220) / SUM( z.winner ),1) END AS AveWinDist,
sum(Placer) as Placers,
sum(PLaceProfit) as PlaceProfit,
ROUND(((SUM(CASE WHEN z.Placer = 1 THEN 1 ELSE 0 END) / COUNT(*)) * 100),2) AS PlacePct,
case when SUM(placer) = 0 then NULL else
round((SUM(CASE WHEN z.Placer = 1 THEN z.distance_yards ELSE 0 END)/220) / SUM( z.Placer ),1) END AS AvePlaceDist
from (
select
hru.sire_name , hra.distance_yards,hru.starting_price_decimal,hru.days_since_ran , hra.class, hru.finish_position ,
case when hru.finish_position = 1 then 1 else 0 end as Winner,
case when num_runners < 8 then case when finish_position in ( 2) then 1 else 0 end
else
case when num_runners < 16 then case when finish_position in ( 2,3) then 1 else 0 end
else
case when handicap = 1 then case when finish_position in (2,3,4) then 1 else 0 end
else
case when finish_position in ( 1,2,3) then 1 else 0 end
end end end as Placer,
round(CASE WHEN finish_position = 1 THEN (starting_price_decimal -1) ELSE -1 END,2) AS WinProfit,
round(case when (
Case when num_runners < 5 then case when finish_position = 1 then 1 else 0 end
else
case when num_runners < 8 then case when finish_position in ( 1,2) then 1 else 0 end
else
case when num_runners < 16 then case when finish_position in ( 1,2,3) then 1 else 0 end
else
case when handicap = 1 then case when finish_position in (1,2,3,4) then 1 else 0 end
else
case when finish_position in ( 1,2,3) then 1 else 0
end end end end end )
= 1
then (starting_price_decimal -1) /
Case when num_runners < 5 then 1
else
case when num_runners < 8 then 4
else
case when num_runners < 12 then 5
else
case when handicap = 1 then 4 else 5
end end end end else -1 end,2)
PlaceProfit
from today_2yoturf_races
join historic_runners hru using (sire_name)
join historic_races hra on hru.race_id = hra.race_id
where hra.race_type_Id = 12
and hra.max_age = 2
and in_race_comment <> 'Withdrawn'
and starting_price_decimal IS NOT NULL
) z
group by z.sire_name
order by z.sire_name);
--
-- Create current 2yo turf runners with sire stats
select CONCAT(substr(tdr.scheduled_time, 9, 2),'-',substr(tdr.scheduled_time, 6, 2)) as Date,
substr(tdr.scheduled_time, 11, 6) as Time, tdr.course as Course,
tdr.cloth_number as 'No.', Draw, tdr.name as Name,
case when tdr.forecast_price_decimal is NULL then 'Res' else tdr.forecast_price_decimal - 1 end as FSP,
CONCAT(substr(tdr.foaling_date, 9, 2),'-',substr(tdr.foaling_date, 6, 2)) as DOB,
Trainer, Jockey,
tds.sire_name Sire, tds.Runners,
tds.Winners, tds.WinProfit, tds.WinPct, IFNULL(tds.AveWinDist,'-') AveWinDist,
tds.Placers, tds.PlaceProfit, tds.PlacePct, IFNULL(tds.AvePlaceDist,'-') AvePlaceDist
from today_2yoturf_races tdr
left join hist_2yoturf_sires tds using (sire_name)
order by tdr.scheduled_time, tdr.course, tds.WinPct desc;
The notes in the query tell you what’s going on at every stage. Copy and paste this query into your favourite MySQL client – Heidi, MySQL Workbench, or Sequel Pro on Mac – and after a few seconds you’ll have the top contenders for tomorrow’s two year old racing, too.
Loops With R – Creating a Racecard with Trainer and Jockey Stats
By Phill Clarke on Tuesday, June 19th, 2018Yesterday we looked at how to create a function in order to easily run the same set of code multiple times, without having to manually edit the code every time. While this is a highly useful concept to understand, we’re still left with manually applying the trainer and jockey combinations for each runner. It remains a time consuming task. Therefore, this article covers creating a basic for loop to iterate over the rows of a dataframe and apply a function to each of them.
There are many ways to loop over the rows of a dataframe, list or matrix in R. Some methods are more efficient than others, while some are perhaps more logical than others. Specifically this article demonstrates how to apply a for loop, which rightly receives some criticism for being slow to execute in certain circumstances. For our purposes, with a limited number of rows, this will not be a problem. However, the reader should investigate R’s apply family of functions and also the map function in the purrr library.
The full R code will be provided within the article, as there have been some useful changes made to code used previously. The complete code will also, as usual, be provided at the end of this article.
Begin by returning historic racing results, this time since 2013 for a full five year dataset and also from tomorrow’s race card:
# Load the library packages
library("RMySQL")
library("dplyr")
# Connect to the Smartform database. Substitute the placeholder credentials for your own.
# The IP address can be substituted for a remote location if appropriate.
con <- dbConnect(MySQL(),
host='127.0.0.1',
user='yourusername',
password='yourpassword',
dbname='smartform')
# Select relevant historic results
sql1 <- paste("SELECT historic_races.course,
historic_races.meeting_date,
historic_races.conditions,
historic_races.group_race,
historic_races.race_type_id,
historic_races.race_type,
historic_runners.name,
historic_runners.jockey_name,
historic_runners.trainer_name,
historic_runners.finish_position,
historic_runners.starting_price_decimal
FROM smartform.historic_runners
JOIN smartform.historic_races USING (race_id)
WHERE historic_races.meeting_date >= '2012-01-01'", sep="")
smartform_results <- dbGetQuery(con, sql1)
# Select relevant daily results for tomorrow
sql2 <- paste("SELECT daily_races.course,
daily_races.race_title,
daily_races.meeting_date,
daily_runners.cloth_number,
daily_runners.name,
daily_runners.trainer_name,
daily_runners.jockey_name,
daily_runners.forecast_price_decimal
FROM smartform.daily_races
JOIN smartform.daily_runners USING (race_id)
WHERE daily_races.meeting_date >='2018-06-20'", sep="")
smartform_daily_results <- dbGetQuery(con, sql2)
dbDisconnect(con)
Next is the Trainer/Jockey function explained yesterday. However, the code will be broken into a few sections, as there have been some changes incorporated.
The function, as detailed previously:
# Name the function and add some arguments
tj <- function(race_filter = "", price_filter = 1000, trainer, jockey){
# Filter for flat races only
flat_races_only <- dplyr::filter(smartform_results,
race_type_id == 12 |
race_type_id == 15)
# Add an if else statement for the race_filter argument
if (race_filter == "group"){
filtered_races <- dplyr::filter(flat_races_only,
group_race == 1 |
group_race == 2 |
group_race == 3 )
} else {
filtered_races = flat_races_only
}
# Filter by trainer name
trainer_filtered <- dplyr::filter(filtered_races,
grepl(trainer, trainer_name))
# Remove non-runners
trainer_name_filtered <- dplyr::filter(trainer_filtered, !is.na(finish_position))
# Filter by jockey name
trainer_jockey_filtered <- dplyr::filter(trainer_filtered,
grepl(jockey, jockey_name))
# Filter by price
trainer_jockey_price_filtered <- dplyr::filter(trainer_jockey_filtered,
starting_price_decimal <= price_filter)
# Calculate Profit and Loss
trainer_jockey_cumulative <- cumsum(
ifelse(trainer_jockey_price_filtered$finish_position == 1,
(trainer_jockey_price_filtered$starting_price_decimal-1),
-1)
)
# Calculate Strike Rate
winners <- nrow(dplyr::filter(trainer_jockey_price_filtered,
finish_position == 1))
runners <- nrow(trainer_jockey_price_filtered)
strike_rate <- (winners / runners) * 100
# Calculate Profit on Turnover or Yield
profit_on_turnover <- (tail(trainer_jockey_cumulative, n=1) / runners) * 100
# Check if POT is zero length to catch later errors
if (length(profit_on_turnover) == 0) profit_on_turnover <- 0
The last line above is new. This line is being used to catch any instances where the profit on turnover figure is of zero length. That means that the calculation has not been successful, usually because there were no runners for the combination of trainer and jockey.
Continuing with the function:
# Calculate Impact Values
# First filter all runners by price, to return those just starting at the price_filter or less
all_runners <- nrow(dplyr::filter(filtered_races,
starting_price_decimal <= price_filter))
# Filter all winners by the price filter
all_winners <- nrow(dplyr::filter(filtered_races,
finish_position == 1 &
starting_price_decimal <= price_filter))
# Now calculate the Impact Value
iv <- (winners / all_winners) / (runners / all_runners)
# Calculate Actual vs Expected ratio
# # Convert all decimal odds to probabilities
total_sp <- sum(1/trainer_jockey_price_filtered$starting_price_decimal)
# Calculate A/E by dividing the number of winners, by the sum of all SP probabilities.
ae <- winners / total_sp
# Calculate Archie
archie <- (runners * (winners - total_sp)^2)/ (total_sp * (runners - total_sp))
# Calculate the Confidence figure
conf <- pchisq(archie, df = 1)*100
# Create an empty variable
trainer_jockey <- NULL
# Add all calculated figures as named objects to the variable, which creates a list
trainer_jockey$tj_runners <- runners
trainer_jockey$tj_winners <- winners
trainer_jockey$tj_sr <- strike_rate
trainer_jockey$tj_pot <- profit_on_turnover
trainer_jockey$tj_iv <- iv
trainer_jockey$tj_ae <- ae
trainer_jockey$tj_conf <- conf
# Add an error check to convert all NaN values to zero
final_results <- unlist(trainer_jockey)
final_results[ is.nan(final_results) ] <- 0
# Manipulate the layout of returned results to be a nice dataframe
final_results <- t(as.data.frame(final_results))
rownames(final_results) <- c()
# 2 decimal places only
round(final_results, 2)
# Finally, close the function
}
Once again, there are some new lines in the final part of the function above. The results are checked for NaN values, which again occur if a calculation has failed. It is not possible, for example, to calculate strike rate if there are no runners for the trainer and jockey combination. Error checking such as this will take some time to implement, but does save a lot of headaches later.
The results are then transformed, with t from a long to wide dataframe, the rownames are removed and all results rounded to two decimal places.
Now, we move on to the new section for this article. First, filter the current daily races for Group races only and also create an empty placeholder list.
# Filter tomorrow's races for Group races only
group_races_only <- dplyr::filter(smartform_daily_results,
grepl(paste(c("Group 1", "Group 2", "Group 3"), collapse="|"), race_title))
# Create a placeholder list which will be required later
row <- list()
Then start the for loop, which essentially says for every value of name, which is the column containing the horse’s name, apply the code which follows. This code includes extracing the trainer and jockey names, then executing the function defined earlier. Lastly, the data is iteratively added to the emtpy list and converted to a dataframe.
# Setup the loop
# For each horse in the group_races_only dataframe
for (i in group_races_only$name) {
runner_details = group_races_only[group_races_only$name==i,]
# Extract trainer and jockey names
trainer = runner_details$trainer_name
jockey = runner_details$jockey_name
# Apply the Trainer/Jockey function for Group races only
trainer_jockey_combo <- tj(race_filter = "group",
trainer = trainer,
jockey = jockey)
# Add results row by row to the previously defined list
row[[i]] <- trainer_jockey_combo
# Create a final dataframe
stats_final <- as.data.frame(do.call("rbind", row))
}
As a final piece of code, we bind the new data and the general racing data from the Smartform database in a new variable called racecard. Viewing this racecard will now display the strike rate, profit on turnover, impact value, actual vs expected and confidence figure for every jockey and trainer combination in Group races on tomorrow’s race card. They are of course all at Royal Ascot.
# Create a new variable called racecard. Bind together the generic race details with the newly created stats
racecard <- cbind(group_races_only,stats_final)
This data can now be reviewed for interesting angles. The screenshot below displays the data ordered descending from the highest A/E value. The first thing to notice about the top three entries is the very small sample size, with only three of four runs. However, the fourth entry for Cox and Kirby does have a robust sample size and some very good figures. Shades of Blue in the Queen Mary Stakes tomorrow at Royal Ascot is certainly worth a closer look. As are the Gosden and Dettori trio of Stream of Stars, Cracksman and Purser. This combination already struck three times today with Calyx, Without Parole and Monarch’s Glen.
Good luck!
Questions and queries about this article should be posted as a comment below or on the Betwise Q&A board.
The full R code used in this article is found below.
# Load the library packages
library("RMySQL")
library("dplyr")
# Connect to the Smartform database. Substitute the placeholder credentials for your own.
# The IP address can be substituted for a remote location if appropriate.
con <- dbConnect(MySQL(),
host='127.0.0.1',
user='yourusername',
password='yourpassword',
dbname='smartform')
# Select relevant historic results
sql1 <- paste("SELECT historic_races.course,
historic_races.meeting_date,
historic_races.conditions,
historic_races.group_race,
historic_races.race_type_id,
historic_races.race_type,
historic_runners.name,
historic_runners.jockey_name,
historic_runners.trainer_name,
historic_runners.finish_position,
historic_runners.starting_price_decimal
FROM smartform.historic_runners
JOIN smartform.historic_races USING (race_id)
WHERE historic_races.meeting_date >= '2012-01-01'", sep="")
smartform_results <- dbGetQuery(con, sql1)
# Select relevant daily results for tomorrow
sql2 <- paste("SELECT daily_races.course,
daily_races.race_title,
daily_races.meeting_date,
daily_runners.cloth_number,
daily_runners.name,
daily_runners.trainer_name,
daily_runners.jockey_name,
daily_runners.forecast_price_decimal
FROM smartform.daily_races
JOIN smartform.daily_runners USING (race_id)
WHERE daily_races.meeting_date >='2018-06-20'", sep="")
smartform_daily_results <- dbGetQuery(con, sql2)
dbDisconnect(con)
# Name the function and add some arguments
tj <- function(race_filter = "", price_filter = 1000, trainer, jockey){
# Filter for flat races only
flat_races_only <- dplyr::filter(smartform_results,
race_type_id == 12 |
race_type_id == 15)
# Add an if else statement for the race_filter argument
if (race_filter == "group"){
filtered_races <- dplyr::filter(flat_races_only,
group_race == 1 |
group_race == 2 |
group_race == 3 )
} else {
filtered_races = flat_races_only
}
# Filter by trainer name
trainer_filtered <- dplyr::filter(filtered_races,
grepl(trainer, trainer_name))
# Remove non-runners
trainer_name_filtered <- dplyr::filter(trainer_filtered, !is.na(finish_position))
# Filter by jockey name
trainer_jockey_filtered <- dplyr::filter(trainer_filtered,
grepl(jockey, jockey_name))
# Filter by price
trainer_jockey_price_filtered <- dplyr::filter(trainer_jockey_filtered,
starting_price_decimal <= price_filter)
# Calculate Profit and Loss
trainer_jockey_cumulative <- cumsum(
ifelse(trainer_jockey_price_filtered$finish_position == 1,
(trainer_jockey_price_filtered$starting_price_decimal-1),
-1)
)
# Calculate Strike Rate
winners <- nrow(dplyr::filter(trainer_jockey_price_filtered,
finish_position == 1))
runners <- nrow(trainer_jockey_price_filtered)
strike_rate <- (winners / runners) * 100
# Calculate Profit on Turnover or Yield
profit_on_turnover <- (tail(trainer_jockey_cumulative, n=1) / runners) * 100
# Check if POT is zero length to catch later errors
if (length(profit_on_turnover) == 0) profit_on_turnover <- 0
# Calculate Impact Values
# First filter all runners by price, to return those just starting at the price_filter or less
all_runners <- nrow(dplyr::filter(filtered_races,
starting_price_decimal <= price_filter))
# Filter all winners by the price filter
all_winners <- nrow(dplyr::filter(filtered_races,
finish_position == 1 &
starting_price_decimal <= price_filter))
# Now calculate the Impact Value
iv <- (winners / all_winners) / (runners / all_runners)
# Calculate Actual vs Expected ratio
# # Convert all decimal odds to probabilities
total_sp <- sum(1/trainer_jockey_price_filtered$starting_price_decimal)
# Calculate A/E by dividing the number of winners, by the sum of all SP probabilities.
ae <- winners / total_sp
# Calculate Archie
archie <- (runners * (winners - total_sp)^2)/ (total_sp * (runners - total_sp))
# Calculate the Confidence figure
conf <- pchisq(archie, df = 1)*100
# Create an empty variable
trainer_jockey <- NULL
# Add all calculated figures as named objects to the variable, which creates a list
trainer_jockey$tj_runners <- runners
trainer_jockey$tj_winners <- winners
trainer_jockey$tj_sr <- strike_rate
trainer_jockey$tj_pot <- profit_on_turnover
trainer_jockey$tj_iv <- iv
trainer_jockey$tj_ae <- ae
trainer_jockey$tj_conf <- conf
# Add an error check to convert all NaN values to zero
final_results <- unlist(trainer_jockey)
final_results[ is.nan(final_results) ] <- 0
# Manipulate the layout of returned results to be a nice dataframe
final_results <- t(as.data.frame(final_results))
rownames(final_results) <- c()
# 2 decimal places only
round(final_results, 2)
# Finally, close the function
}
# Filter tomorrow's races for Group races only
group_races_only <- dplyr::filter(smartform_daily_results,
grepl(paste(c("Group 1", "Group 2", "Group 3"), collapse="|"), race_title))
# Create a placeholder list which will be required later
row <- list()
# Setup the loop
# For each horse in the group_races_only dataframe
for (i in group_races_only$name) {
runner_details = group_races_only[group_races_only$name==i,]
# Extract trainer and jockey names
trainer = runner_details$trainer_name
jockey = runner_details$jockey_name
# Apply the Trainer/Jockey function for Group races only
trainer_jockey_combo <- tj(race_filter = "group",
trainer = trainer,
jockey = jockey)
# Add results row by row to the previously defined list
row[[i]] <- trainer_jockey_combo
# Create a final dataframe
stats_final <- as.data.frame(do.call("rbind", row))
}
# Create a new variable called racecard. Bind together the generic race details with the newly created stats
racecard <- cbind(group_races_only,stats_final)