
Pat Cosgrave’s 28 Day Ban
By Henry Young on Saturday, April 22nd, 2023You may have seen that Pat Cosgrave received a 28 day ban for easing what should have been an easy winner on Concord in the Chelmsford 8pm on 20th April 2023. You can read the Racing Post report here:
Of immediate interest to me is why did he do this? While some may suggest dubious intent, my first thought was that as a seasoned jockey, and given the insights into jockey changing room culture that leak out from time to time, perhaps he simply enjoys underlining his seniority there with over the shoulder glances and a “look at me winning with no hands” attitude which he simply misjudged on this occasion. So I wanted to re-watch some of his other big distance wins to assess his riding manner in similar situations.
But how to find these easy win races ?
Smartform to the rescue with a simple SQL query:
mysql> select scheduled_time, name, course, finish_position as position, distance_won as distance from historic_runners_beta join historic_races_beta using (race_id) where jockey_name = "P Cosgrave" and finish_position = 1 order by distance_won desc limit 20;
+---------------------+--------------------+---------------+----------+----------+
| scheduled_time | name | course | position | distance |
+---------------------+--------------------+---------------+----------+----------+
| 2022-07-07 17:53:00 | Caius Chorister | Epsom_Downs | 1 | 19.00 |
| 2006-07-18 19:10:00 | Holdin Foldin | Newcastle | 1 | 17.00 |
| 2003-10-25 17:00:00 | Excalibur | Curragh | 1 | 15.00 |
| 2015-05-20 14:30:00 | Wonder Laish | Lingfield | 1 | 15.00 |
| 2015-10-06 14:10:00 | Light Music | Leicester | 1 | 14.00 |
| 2009-01-29 14:20:00 | More Time Tim | Southwell | 1 | 13.00 |
| 2018-07-19 14:20:00 | Desert Fire | Leicester | 1 | 12.00 |
| 2008-12-12 12:55:00 | Confucius Captain | Southwell | 1 | 10.00 |
| 2010-04-27 16:10:00 | On Her Way | Yarmouth | 1 | 10.00 |
| 2018-09-22 15:55:00 | Stars Over The Sea | Newmarket | 1 | 10.00 |
| 2012-10-25 16:40:00 | Saaboog | Southwell | 1 | 9.00 |
| 2006-03-31 15:40:00 | John Forbes | Musselburgh | 1 | 8.00 |
| 2015-05-20 15:00:00 | I'm Harry | Lingfield | 1 | 8.00 |
| 2018-06-17 15:10:00 | Pirate King | Doncaster | 1 | 8.00 |
| 2019-05-19 17:30:00 | Great Example | Ripon | 1 | 8.00 |
| 2004-07-19 18:30:00 | Orpailleur | Ballinrobe | 1 | 7.00 |
| 2007-07-04 17:35:00 | Serena's Storm | Catterick | 1 | 7.00 |
| 2008-01-07 13:50:00 | Home | Southwell | 1 | 7.00 |
| 2014-09-06 20:50:00 | Fiftyshadesfreed | Wolverhampton | 1 | 7.00 |
| 2015-05-16 13:45:00 | Firmdecisions | Newmarket | 1 | 7.00 |
+---------------------+--------------------+---------------+----------+----------+
20 rows in set (5.55 sec)
You can watch the top race here, with no apparent easing but plenty of glances behind:
The point of this article is really to emphasize that with Smartform and a modicum of SQL knowledge, you can easily answer those oddball questions that come up from time to time, that no existing software solution or website will answer as easily.
Improvements to advance racecards in Smartform
By colin on Sunday, March 12th, 2023The daily_racecards and daily_runners tables have always provided racecards as early as they were available (usually two days ahead of the meetings, but for big races sometimes as many as five days ahead).
This provides benefits for users doing advance race analysis but presents some issues in ensuring that the most up-to-date cards are available – for example, reflecting latest non-runners, jockey changes, or race time changes – in daily cards
Improvements
To improve both use cases from now on, the daily_racecards and daily_runners tables (and their equivalent in the beta database) will provide new racecards only on the evening before the meetings, so they will always carry the final declarations.
To complement this and enable analysis more than 24 hours before racing, we have added new database feeds with equivalent tables to daily* for advance racecards for both the original and beta database products. These two feeds will provide the card on the first available day it is available to us, usually up to two days in advance, or more for big race meetings.
Making it all work for your subscription
daily* tables
There is nothing that you need to do in order to keep receiving daily updates, and in fact your database will now receive more up to date information (reflecting the final declarations) for the next day. However, these tables will no longer contain any data more than one day in advance of the race. If you want tomorrow’s cards earlier than 7.30 pm the day before the race, or the cards for racing the day after tomorrow, look to advance race cards, as below…
advance* tables
To receive the advance* data, you can jump straight to download details for the individual products at the following links:
Original database: https://www.betwise.co.uk/smartform/advance_racecards
Beta database: https://www.betwise.co.uk/smartform/advance_racecards_beta
So for the upcoming Cheltenham meeting, for example, you will soon see the earliest cards for advance analysis in the advance* tables, and the most up to date cards in the daily* tables the evening before racing.
The Johnstons : Mark > Mark & Charlie > Charlie
By Henry Young on Friday, February 10th, 2023The Johnstons have become a racing dynasty. Mark Johnston first registered his trainer’s license in 1987. In 2009 he became the first flat trainer to send out more than 200 winners in a single season (2009). He went on to repeat that feat in 2010, 2012, 2013, 2014, 2015, 2017, 2018, 2019 and 2021. His son Charlie was brought up to follow in his father’s footsteps and take over the family business. He started working full time for Mark in 2016, and joined his father on their joint trainers license in late January 2022, with Mark leaving the license from January 2023.
The key question for us is what implication does this have for the data in the Smartform database. Let’s take a look at the trainer_id values:
select distinct trainer_name, trainer_id from historic_runners_beta where trainer_name like "%Johnston";
+-------------------------+------------+
| trainer_name | trainer_id |
+-------------------------+------------+
| M Johnston | 1883 |
...
| Charlie & Mark Johnston | 1883 |
| Charlie & Mark Johnston | NULL |
| Charlie Johnston | 154458 |
+-------------------------+------------+
7 rows in set (5.72 sec)Note there are three other unrelated Johnstons whom I have removed from the results table for clarity.
The first thing we see is that when Charlie joined the trainer license, the trainer_id remained the same. But when Mark left the license, a new trainer_id was created for Charlie on his own. If you take the view that nothing significant has changed about how the yard is run, the staff, the training methods, etc, you may prefer to see results from all three Johnston licenses under a single trainer_id.
But there is one other oddity. One or more of the Charlie & Mark Johnston results have a NULL trainer_id. That is a data error you may wish to correct. Further digging reveals that the NULL issue exists for 455 runners between 24/08/2022 and 31/12/2022. Let’s deal with this fix first.
The following SQL statement will correct all instances of the NULL trainer_id problem:
SET SQL_SAFE_UPDATES = 0;
UPDATE historic_runners_beta SET trainer_id = 1883 WHERE trainer_name = "Charlie & Mark Johnston";
SET SQL_SAFE_UPDATES = 1;But if you prefer all the runners for all three Johnston licenses to be combined under a single trainer_id, simply use the following instead:
SET SQL_SAFE_UPDATES = 0;
UPDATE historic_runners_beta SET trainer_id = 154458 WHERE trainer_name = "Charlie & Mark Johnston";
UPDATE historic_runners_beta SET trainer_id = 154458 WHERE trainer_name = "M Johnston";
SET SQL_SAFE_UPDATES = 1;Note that here we are using the newest trainer_id to tag all past results. This means the modification is a one-time deal and all future runners/races will continue to use the same trainer_id. If we had used the original M Johnston trainer_id value of 1883, we would have to apply the fix script every day, which would be far less convenient.
If you find there are other trainer name changes that have resulted in a new trainer_id which you would prefer to see merged, you can apply similar techniques. As a general rule, when new names are added to existing licenses, the trainer_id remains the same. But when names are removed from joint licenses, a new trainer_id is issued. But please check on a case by case basis, because rules often have exceptions !
The key takeaway is that you can create your own groupings with Smartform where you think such groupings are appropriate, without altering any of the source data.
If you know of other cases of trainer name changes which represent a continuation of substantially the same yard, please feel free to comment …
Adding data to Smartform
By Henry Young on Friday, December 23rd, 2022Using Smartform typically involves querying and aggregating data by various criteria. For example you may wish to look into trainer strike rate by course and race type, in effect regenerating the same data that used to be painstakingly manually compiled by Ken Turrell in his annual publication Trainers4Courses:

Ken no longer produces his book, but the key data can be generated from Smartform through a single SQL query:
SELECT
sub.course,
sub.race_type,
sub.race_type_id,
sub.trainer_name,
sub.trainer_id,
sub.RaceCount,
sub.WinCount,
percentage(sub.RaceCount, sub.WinCount, 30, 1) AS WinPct
FROM (
SELECT
course,
ANY_VALUE(race_type) AS race_type,
race_type_id,
ANY_VALUE(trainer_name) AS trainer_name,
trainer_id,
COUNT(*) AS RaceCount,
COUNT(IF(finish_position = 1, 1, NULL)) AS WinCount
FROM
historic_races_beta
JOIN
historic_runners_beta USING (race_id)
GROUP BY trainer_id, course, race_type_id) AS sub
ORDER BY sub.course, sub.race_type_id, sub.trainer_name;
If you feed the results into a new table, which requires some additional syntactic sugar along the lines of a previous blog post, you can then pull trainer strike rates per course into your custom race cards. Doing so requires a SQL table join between the new table, daily_races_beta and daily_runners_beta, joining on course and race_type_id. But when you try to do that table join, you’ll discover that race_type_id is not available in daily_races_beta (or its forerunner daily_races). The same information is implied by a combination of race_type and track_type. The easiest option is to add this column into the original Smartform table and populate it yourself.
When adding a new column to an existing Smartform table, there is the obvious concern that this may be overwritten by the daily updates, and certainly remain unpopulated by those updates. The answer is to add the column with DEFAULT NULL and then run a script daily after the updater has completed. That script should add the new column if required, and populate any NULL values. Next we look into the details of how to achieve this.
The first thing we should do is to create a stored function that generates a value for race_type_id based on race_type and track_type. Let’s call that function get_race_type_id.
delimiter //
DROP FUNCTION IF EXISTS get_race_type_id//
CREATE FUNCTION get_race_type_id(race_type varchar(30), track_type varchar(30)) RETURNS smallint
COMMENT 'convert race_type/track_type strings to race_type_id'
DETERMINISTIC
NO SQL
BEGIN
RETURN
CASE race_type
WHEN 'Flat' THEN if (track_type = 'Turf', 12, 15)
WHEN 'Hurdle' THEN 14
WHEN 'Chase' THEN 13
WHEN 'National Hunt Flat' THEN 1
WHEN 'N_H_Flat' THEN 1
WHEN 'All Weather Flat' THEN 15
END;
END//
delimiter ;
You can see that the function is obviously handling some peculiarities of how the data appears in Smartform. With this function defined we can proceed to define the SQL stored procedure which can be called daily after the Smartform updater – a process that can easily be automated by using a scheduled script according to whichever operating system you’re using:
-- Check if the column 'race_type_id' exists in table 'daily_races_beta'
-- Add the missing column if necessary
-- Populate values based on 'race_type' and 'track_type'
delimiter //
DROP PROCEDURE IF EXISTS fix_race_type_id//
CREATE PROCEDURE fix_race_type_id()
COMMENT 'Adds race_type_id to daily_races_beta if necessary and populates NULL values'
BEGIN
IF NOT EXISTS (
SELECT * FROM information_schema.columns
WHERE column_name = 'race_type_id' AND
table_name = 'daily_races_beta' AND
table_schema = 'smartform' )
THEN
ALTER TABLE smartform.daily_races_beta
ADD COLUMN race_type_id SMALLINT UNSIGNED DEFAULT NULL;
END IF;
SET SQL_SAFE_UPDATES = 0;
UPDATE daily_races_beta
SET race_type_id = get_race_type_id(race_type, track_type)
WHERE race_type_id IS NULL;
SET SQL_SAFE_UPDATES = 1;
END//
delimiter ;
The most complicated aspect of the above is the hoop you have to jump through in MySQL to discover if a column exists – querying information_schema.columns. Do we really need to do this every time ? No – but it’s a useful fail-safe in case the database has to be reloaded from bulk download at any stage.
In conclusion, adding new columns to existing Smartform tables is sometimes the most convenient solution to a requirement and can be done safely if you follow a few simple rules.
Expected Race Duration
By Henry Young on Thursday, July 28th, 2022When developing real time automated in-play betting strategies, variation in price is the fastest source of information available in order to infer the action in the race. This is due to the volume in betting from a large number of in-running players watching the action, some using live video drone feeds, causing prices to contract and expand depending on the perceived chances of runners in the race.
However, the interpretation of price variation caused by in-running betting depends critically on what stage the race is at. For example, a price increase at the start may be due to a recoverable stumble out of the gates, whereas price lengthening in the closing stages of a race strongly suggests a loser. This is why it is invaluable to have an estimate of the expected race duration.
Similarly, if you are building an in-play market making system, offering liquidity on both the back and lay side with a view to netting the spread, you may wish to close out or green up your positions prior to the most volatile period of the race which is typically the final furlong. Running a timer from the “off” signal using expected race duration minus, say 10 or 15 seconds, is critically important for this purpose.
A crude estimate of expected race duration can be calculated by multiplying race distance by speed typical for that distance. For example, sprints are typically paced at 11-12 seconds per furlong, whereas middle distance races are typically 13+seconds per furlong. Greater accuracy needs to account for course specifics – sharpness, undulation, uphill/downhill, etc.
Fortunately SmartForm contains a historic races field winning_time_secs. Therefore we can query for the min/max/average of this field for races at the course and distance in question. But this immediately throws up the problem that race distances in SmartForm are in yards, apparently measured with sub-furlong accuracy. If you want the data for 5f races, simply querying for 5 x 220 = 1,100 yards is not going to give you the desired result. Actual race distances vary according to the vagaries of doling out rails to avoid bad ground, how much the tractor driver delivering the starting gates had to drink the night before, etc. We need to work in furlongs by rounding the yards based distance data. Therefore we should first define a convenient MySQL helper function:
CREATE
DEFINER='smartform'@'localhost'
FUNCTION furlongs(yards INT) RETURNS INT
COMMENT 'calculate furlongs from yards'
DETERMINISTIC
NO SQL
BEGIN
RETURN round(yards/220, 0);
ENDNow we can write a query using this function to get expected race duration for 6f races at Yarmouth:
SELECT
min(winning_time_secs) as course_time
FROM
historic_races_beta
WHERE
course = "Yarmouth" AND
furlongs(distance_yards) = 6 and
meeting_date > "2020-01-01";With the result being:
+-------------+
| course_time |
+-------------+
| 68.85 |
+-------------+
1 row in set (0.40 sec)The query runs through all Yarmouth races over all distances in yards which when rounded equate to 6f, calculating the minimum winning time – in effect the (recent) course record. The min could be replaced by max or avg according to needs. My specific use case called for a lower bound on expected race duration, hence using min. Note the query only uses recent races (since 01 Jan 2020) to reduce the possibility of historic course layout changes influencing results. You may prefer to tailor this per course. For example Southwell’s all weather track change from Fibersand to the faster Tapeta in 2021 would demand exclusion of all winning times on the old surface, although the use of min should achieve much the same effect.
Now that we understand the basic idea, we have to move this into the real world by making these queries from code – Python being my language of choice for coding trading bots.
The following is a Python function get_course_time to which you pass a Betfair market ID and which returns expected race duration based on recent prior race results. The function runs through a sequence of three queries which in turn:
- Converts from Betfair market ID to SmartForm race_id using
daily_betfair_mappings - Obtains course, race_type and distance in furlongs for the race in question using
daily_races_beta - Queries
historic_races_betafor the minimum winning time at course and distance
If there are no relevant results in the database, a crude course time estimate based on 12 x distance in furlongs is returned.
import pymysql
def get_course_time(marketId):
query_SmartForm_raceid = """select distinct race_id from daily_betfair_mappings
where bf_race_id = %s"""
query_race_parameters = """select course, race_type, furlongs(distance_yards) as distance from daily_races_beta
where race_id = %s"""
query_course_time = """select min(winning_time_secs) as course_time from historic_races_beta
where course = %s and
race_type = %s and
furlongs(distance_yards) = %s and
meeting_date > %s"""
base_date = datetime(2020, 1, 1)
# Establish connection to Smartform database
connection = pymysql.connect(host='localhost', user='smartform', passwd ='smartform', database = 'smartform')
with connection.cursor(pymysql.cursors.DictCursor) as cursor:
# Initial default time based on typical fast 5f sprint
default_course_time = 60.0
# Get SmartForm race_id
cursor.execute(query_SmartForm_raceid, (marketId))
rows = cursor.fetchall()
if len(rows):
race_id = rows[0]['race_id']
else:
return default_course_time
# Get race parameters required for course time query
cursor.execute(query_race_parameters, (race_id))
rows = cursor.fetchall()
if len(rows):
course = rows[0]['course']
race_type = rows[0]['race_type']
distance = rows[0]['distance']
else:
return default_course_time
# Improved default time based on actual race distance using 12s per furlong
default_course_time = distance * 12
# Get minimum course time
cursor.execute(query_course_time, (course, race_type, distance, base_date))
rows = cursor.fetchall()
if len(rows):
course_time = rows[0]['course_time']
if course_time is None:
return default_course_time
if course_time == 0.0:
return default_course_time
else:
return default_course_time
return course_time
Trainers’ Intentions – Jockey Bookings
By Henry Young on Friday, May 20th, 2022Trainers tell us a lot about their runners’ chances of winning through factors such as race selection and jockey bookings. For example, trainers will sometimes run horses on unsuitable going, or at an unsuitable course or over an unsuitable distance with the intention of obtaining a handicap advantage which they plan to cash in on with a future race. I see this happening a lot in May-July, presumably with a view to winning the larger prizes available later in the flat season.
Information about trainers’ intentions can also be inferred from their jockey bookings. Most trainers have a few favoured jockeys who do the majority of their winning, with the remainder necessarily below average. This shows up in the trainer/jockey combo stats which are easily computed using Smartform, as we will see shortly. For example, Luke Morris – legendary as one of the hardest working jockeys with 16,700 races ridden since 2010 – has ridden most races for Sir Mark Prescott (1,849) at a strike rate of 19%. While he has higher strike rates with a few other trainers, these carry far less statistical significance. But you’ll often see him riding outsiders for a wide range of other trainers. The take away is never lay the Prescott/Morris combo !
When I assess a race, I find myself asking “Why is this jockey here today?”. If you assess not the race but each jockey’s bookings on the day, it give an interesting alternative perspective, clearly differentiating between regular or preferred trainer bookings and “filler” bookings. This latter variety of booking is normally associated with lower strike rates and therefore can be used as a factor to consider when analyzing a race, particularly for lay candidates.
Before diving into how to do this analysis, let me give you an example from Redcar on 18th April 2022 as I write this. While analyzing the 14:49 race, I became interested in one particular runner as a lay candidate and asked the question “Why is this jockey here today?”. In the following table you can see each of the jockey’s engagements for that day with the trainer/jockey combo strike rate (for all races at all courses since 2010):
+---------------------+--------+----------------+-------------+-------------------+-----------+----------+-------+
| scheduled_time | course | runner_name | jockey_name | trainer_name | RaceCount | WinCount | SR_TJ |
+---------------------+--------+----------------+-------------+-------------------+-----------+----------+-------+
| 2022-04-18 13:39:00 | Redcar | Mahanakhon | D Allan | T D Easterby | 4225 | 499 | 11.8 |
| 2022-04-18 14:14:00 | Redcar | Mr Moonstorm | D Allan | T D Easterby | 4225 | 499 | 11.8 |
| 2022-04-18 14:49:00 | Redcar | The Golden Cue | D Allan | Steph Hollinshead | 14 | 1 | 7.1 |
| 2022-04-18 15:24:00 | Redcar | Ugo Gregory | D Allan | T D Easterby | 4225 | 499 | 11.8 |
| 2022-04-18 15:59:00 | Redcar | Hyperfocus | D Allan | T D Easterby | 4225 | 499 | 11.8 |
| 2022-04-18 16:34:00 | Redcar | The Grey Wolf | D Allan | T D Easterby | 4225 | 499 | 11.8 |
| 2022-04-18 17:44:00 | Redcar | Eruption | D Allan | T D Easterby | 4225 | 499 | 11.8 |
+---------------------+--------+----------------+-------------+-------------------+-----------+----------+-------+The answer is clearly that D Allan was at Redcar to ride for Tim Easterby and had taken the booking for Steph Hollinshead as a “filler”. “The Golden Cue” subsequently finished 17th out of 20 runners.
Performing this analysis on a daily basis is a two stage process. First, we need to calculate trainer/jockey combo strike rates. Then we use that data in combination with the daily races data to list each of a specific jockey’s bookings for the day. Let’s start with the last part to warm up our SQL mojo:
SELECT
scheduled_time,
course,
name as runner_name,
jockey_name,
trainer_name
FROM
daily_races_beta
JOIN
daily_runners_beta
USING (race_id)
WHERE
meeting_date = "2022-04-18" AND
jockey_name = "D Allan"
ORDER BY scheduled_time;This gets us the first 5 columns of the table above, without the strike rate data:
+---------------------+--------+----------------+-------------+-------------------+
| scheduled_time | course | runner_name | jockey_name | trainer_name |
+---------------------+--------+----------------+-------------+-------------------+
| 2022-04-18 13:39:00 | Redcar | Mahanakhon | D Allan | T D Easterby |
| 2022-04-18 14:14:00 | Redcar | Mr Moonstorm | D Allan | T D Easterby |
| 2022-04-18 14:49:00 | Redcar | The Golden Cue | D Allan | Steph Hollinshead |
| 2022-04-18 15:24:00 | Redcar | Ugo Gregory | D Allan | T D Easterby |
| 2022-04-18 15:59:00 | Redcar | Hyperfocus | D Allan | T D Easterby |
| 2022-04-18 16:34:00 | Redcar | The Grey Wolf | D Allan | T D Easterby |
| 2022-04-18 17:44:00 | Redcar | Eruption | D Allan | T D Easterby |
+---------------------+--------+----------------+-------------+-------------------+There are two approaches to generating the trainer/jockey strike rate data – using a sub-query or creating a new table of all trainer/jockey combo strike rates. I normally take the latter approach because I use this type of data many times over during the day. I therefore have this setup as a stored procedure which is run daily after the database update. The following SQL is executed once to (re)define the stored procedure called refresh_trainer_jockeys:
delimiter //
DROP PROCEDURE IF EXISTS refresh_trainer_jockeys//
CREATE
DEFINER='smartform'@'localhost'
PROCEDURE refresh_trainer_jockeys()
COMMENT 'Regenerates the x_trainer_jockeys table'
BEGIN
DROP TABLE IF EXISTS x_trainer_jockeys;
CREATE TABLE x_trainer_jockeys (
trainer_name varchar(80),
trainer_id int(11),
jockey_name varchar(80),
jockey_id int(11),
RaceCount int(4),
WinCount int(4),
WinPct decimal(4,1));
INSERT INTO x_trainer_jockeys
SELECT
sub.trainer_name,
sub.trainer_id,
sub.jockey_name,
sub.jockey_id,
sub.RaceCount,
sub.WinCount,
percentage(sub.RaceCount, sub.WinCount, 20, 1) AS WinPct
FROM (
SELECT
ANY_VALUE(trainer_name) AS trainer_name,
trainer_id,
ANY_VALUE(jockey_name) AS jockey_name,
jockey_id,
COUNT(*) AS RaceCount,
COUNT(IF(finish_position = 1, 1, NULL)) AS WinCount
FROM
historic_races_beta
JOIN
historic_runners_beta
USING (race_id)
WHERE
YEAR(meeting_date) >= 2010 AND
trainer_id IS NOT NULL AND
jockey_id IS NOT NULL AND
NOT (unfinished <=> "Non-Runner")
GROUP BY jockey_id, trainer_id) AS sub
ORDER BY sub.trainer_name, sub.jockey_name;
END//
delimiter ;When the stored procedure refresh_trainer_jockeys is run, a new table x_trainer_jockeys is created. This new table is very useful for queries such as:
SELECT * FROM x_trainer_jockeys WHERE trainer_name = "W J Haggas" ORDER BY WinPct DESC LIMIT 20;which results in the strike rates for William Haggas’ top 20 jockeys (for all races at all courses since 2010):
+--------------+------------+---------------+-----------+-----------+----------+--------+
| trainer_name | trainer_id | jockey_name | jockey_id | RaceCount | WinCount | WinPct |
+--------------+------------+---------------+-----------+-----------+----------+--------+
| W J Haggas | 1804 | S Sanders | 4355 | 70 | 25 | 35.7 |
| W J Haggas | 1804 | B A Curtis | 45085 | 109 | 35 | 32.1 |
| W J Haggas | 1804 | L Dettori | 2589 | 90 | 28 | 31.1 |
| W J Haggas | 1804 | D Tudhope | 27114 | 225 | 69 | 30.7 |
| W J Haggas | 1804 | T P Queally | 18614 | 49 | 15 | 30.6 |
| W J Haggas | 1804 | G Gibbons | 18303 | 80 | 24 | 30.0 |
| W J Haggas | 1804 | A Kirby | 31725 | 28 | 8 | 28.6 |
| W J Haggas | 1804 | R Kingscote | 31611 | 79 | 22 | 27.8 |
| W J Haggas | 1804 | Jim Crowley | 43145 | 270 | 74 | 27.4 |
| W J Haggas | 1804 | S De Sousa | 41905 | 84 | 23 | 27.4 |
| W J Haggas | 1804 | R L Moore | 18854 | 360 | 91 | 25.3 |
| W J Haggas | 1804 | P Hanagan | 16510 | 355 | 88 | 24.8 |
| W J Haggas | 1804 | A J Farragher | 1165464 | 53 | 13 | 24.5 |
| W J Haggas | 1804 | J Fanning | 2616 | 128 | 31 | 24.2 |
| W J Haggas | 1804 | J Doyle | 31684 | 455 | 105 | 23.1 |
| W J Haggas | 1804 | Oisin Murphy | 1151765 | 66 | 15 | 22.7 |
| W J Haggas | 1804 | M Harley | 74041 | 76 | 17 | 22.4 |
| W J Haggas | 1804 | Tom Marquand | 1157192 | 705 | 157 | 22.3 |
| W J Haggas | 1804 | R Hughes | 1764 | 81 | 18 | 22.2 |
| W J Haggas | 1804 | P Cosgrave | 17562 | 564 | 121 | 21.5 |
+--------------+------------+---------------+-----------+-----------+----------+--------+We’re now ready to use x_trainer_jockeys to complete the answer to our question “Why is this jockey here today?”:
SELECT
scheduled_time,
course,
name as runner_name,
daily_runners_beta.jockey_name,
daily_runners_beta.trainer_name,
coalesce(RaceCount, 0) as RaceCount,
coalesce(WinCount, 0) as WinCount,
coalesce(WinPct, 0.0) as SR_TJ
FROM
daily_races_beta
JOIN
daily_runners_beta
USING (race_id)
LEFT JOIN
x_trainer_jockeys
USING (trainer_id,jockey_id)
WHERE
meeting_date = "2022-04-18" AND
daily_runners_beta.jockey_name = "D Allan"
ORDER BY scheduled_time;Which comes full circle, giving us the table at the top of the blog !
Making use of Days Since Last Run
By Henry Young on Thursday, March 31st, 2022I have learned the hard way that a quick turnaround is a red flag for laying. Trainers will sometimes run a horse again only a few days after a much improved run or a win. They do this to capitalize on a horse coming into form, especially in handicaps to beat the handicapper reassessment delay. But how can we quantify the impact of this phenomenon, whether for use in a custom racecard analysis or for feeding into a machine learning (ML) system.
Smartform contains a field “days_since_ran” in both daily_runners and historic_runners tables. However, seeing that a runner last ran x days ago does not really tell you much other than a little of what’s in the trainer’s mind. And this data point is completely unsuitable for passing on to ML because it is not normalized. The easiest solution is to convert it into a Strike Rate percentage:
Strike Rate = Number of wins / Number of races
We need to count races, count wins and calculate Strike Rate percentages. This can be done in SQL as follows:
SELECT
sub.days_since_ran,
sub.race_count,
sub.win_count,
round(sub.win_count / sub.race_count * 100, 1) AS strike_rate
FROM (
SELECT
days_since_ran,
COUNT(*) as race_count,
COUNT(IF(finish_position = 1, 1, NULL)) AS win_count
FROM
historic_runners_beta
JOIN
historic_races_beta
USING(race_id)
WHERE
days_since_ran IS NOT NULL AND
year(meeting_date) >= 2010
GROUP BY days_since_ran
ORDER BY days_since_ran LIMIT 50) AS sub;You can see a neat trick for counting wins in line 10.
This is structured as a nested query because the inner SELECT does the counting with runners grouped by days_since_ran, while the outer SELECT calculates percentages using the counted totals per group. I find myself using this nested query approach frequently – counting in the inner and calculating in the outer.
The first 15 lines of the resulting table looks like this:
+----------------+------------+-----------+-------------+
| days_since_ran | race_count | win_count | strike_rate |
+----------------+------------+-----------+-------------+
| 1 | 5051 | 210 | 4.2 |
| 2 | 7250 | 566 | 7.8 |
| 3 | 7839 | 988 | 12.6 |
| 4 | 10054 | 1397 | 13.9 |
| 5 | 13139 | 1705 | 13.0 |
| 6 | 17978 | 2176 | 12.1 |
| 7 | 34955 | 3892 | 11.1 |
| 8 | 29427 | 3064 | 10.4 |
| 9 | 31523 | 3174 | 10.1 |
| 10 | 33727 | 3242 | 9.6 |
| 11 | 36690 | 3411 | 9.3 |
| 12 | 39793 | 3854 | 9.7 |
| 13 | 42884 | 4039 | 9.4 |
| 14 | 61825 | 5771 | 9.3 |
| 15 | 44634 | 4303 | 9.6 |Here we can see that Strike Rate has an interesting peak around 3-7 days since last run. But is this the same for handicaps and non-handicaps ? We can answer that question easily by adding an extra WHERE clause to slice and dice the data. We insert this after the WHERE on line 16:
handicap = 1 ANDrerun the SQL then switch it to:
handicap = 0 ANDand run it again.
We can then paste the output into three text files, import each into Excel, and turn it into a chart:
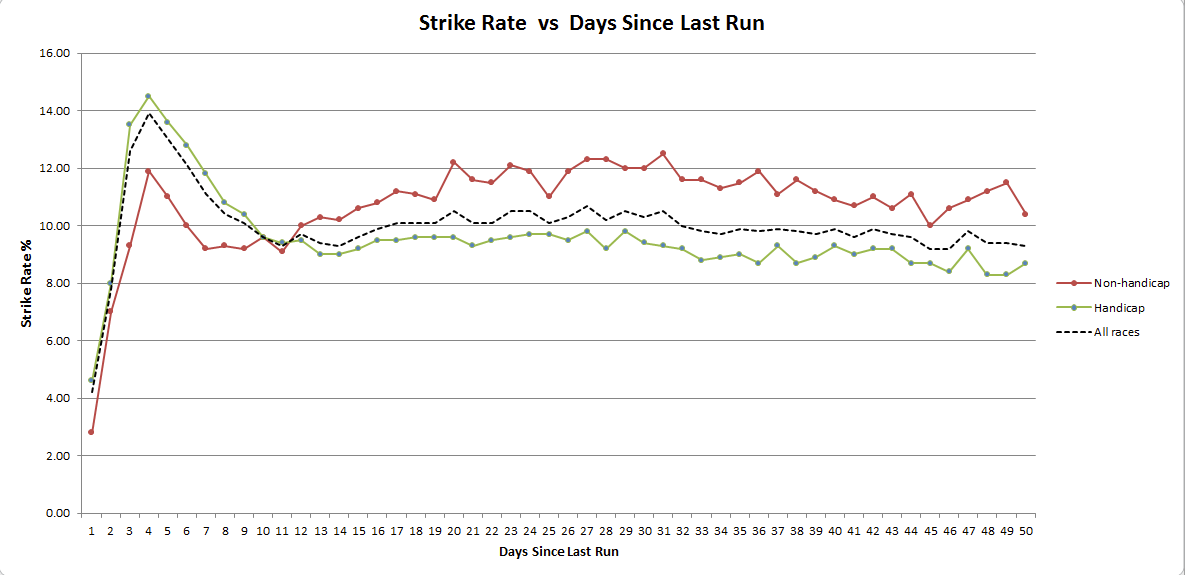
We can see that the quick turnaround Strike Rate peak is most pronounced in handicaps. But for non-handicaps the notable feature is really a lowering of Strike Rate in the 7-14 day range. It’s also interesting to see that handicaps generally have a lower Strike Rate than non-handicaps, perhaps due to field size trends. And as you would expect, running within one or two days of a prior run is rarely a good idea !
But there’s an even better way to structure a query to return the data for all races, handicaps and non-handicaps by adding the handicap field to both SELECT clauses and the GROUP BY with a ROLLUP for good measure:
SELECT
sub.days_since_ran,
sub.handicap,
sub.race_count,
sub.win_count,
round(sub.win_count / sub.race_count * 100, 1) AS strike_rate
FROM (
SELECT
days_since_ran,
handicap,
COUNT(*) as race_count,
COUNT(IF(finish_position = 1, 1, NULL)) AS win_count
FROM
historic_runners_beta
JOIN
historic_races_beta
USING(race_id)
WHERE
days_since_ran IS NOT NULL AND
year(meeting_date) >= 2010
GROUP BY days_since_ran, handicap WITH ROLLUP
ORDER BY days_since_ran, handicap LIMIT 150) AS sub;The first 15 lines of the resulting table looks like this:
+----------------+----------+------------+-----------+-------------+
| days_since_ran | handicap | race_count | win_count | strike_rate |
+----------------+----------+------------+-----------+-------------+
| NULL | NULL | 1496886 | 145734 | 9.7 |
| 1 | NULL | 5051 | 210 | 4.2 |
| 1 | 0 | 1292 | 36 | 2.8 |
| 1 | 1 | 3759 | 174 | 4.6 |
| 2 | NULL | 7250 | 566 | 7.8 |
| 2 | 0 | 1580 | 110 | 7.0 |
| 2 | 1 | 5670 | 456 | 8.0 |
| 3 | NULL | 7839 | 988 | 12.6 |
| 3 | 0 | 1671 | 155 | 9.3 |
| 3 | 1 | 6168 | 833 | 13.5 |
| 4 | NULL | 10054 | 1397 | 13.9 |
| 4 | 0 | 2300 | 274 | 11.9 |
| 4 | 1 | 7754 | 1123 | 14.5 |
| 5 | NULL | 13140 | 1705 | 13.0 |
| 5 | 0 | 3101 | 341 | 11.0 |
| 5 | 1 | 10039 | 1364 | 13.6 |where the rows with handicap = NULL represent the All Races data. While this is less convenient for importing into Excel to make a chart, it is closer to what you may want as a data mapping table for normalizing data to be passed onto a ML system. The top double NULL row gives the Strike Rate for all runners in all races of all types irrespective of days_since_ran as 9.7% – a useful baseline number.
A question for the reader. If the average Strike Rate for all runners in all races of all types is 9.7%, can you use that information to calculate the average number of runners per race ? And what simple one liner query would you use to check your result ? Answers in the comments please 🙂
The final point to tie up is what if you want to use this as a days_since_ran to Strike Rate conversion so that you can present normalized data to your downstream ML system. The simplest solution is to store this data back into the database as a data mapping table by prefixing the outer SELECT with:
DROP TABLE IF EXISTS days_since_ran_x_strike_rate;
CREATE TABLE days_since_ran_x_strike_rate(
days_since_ran int(4),
handicap tinyint(1),
race_count int(6),
win_count int(6),
strike_rate decimal(4,1));
INSERT INTO days_since_ran_x_strike_rate
SELECT
...You can then use this data mapping table for days_since_ran to Strike Rate conversion by performing a JOIN as follows (incomplete code):
SELECT
strike_rate
FROM
daily_runners
JOIN
days_since_ran_x_strike_rate
USING(days_since_ran)To make this work reliably is a little more complex because once over 50 days you need to bucket day ranges or perhaps have a single bucket for > 50 with the LIMIT 50 removed, which in turn means working CASE into your SQL.
For automation, you can set the whole thing up as a stored procedure which you run daily as a Windows scheduled job or Linux cron job, shortly after your daily database update.
Can you run Smartform on the Raspberry Pi?
By bw_admin on Monday, November 2nd, 2020(Guest post by Mike Houghton, Betwise developer)
As part of the new Smartform beta process, we have recently been playing with the Raspberry Pi 4, a tiny Linux computer that we suspect needs little introduction but which has taken great strides in the last year or so.
If you have until now been unaware of the Raspberry Pi, well, what is it?
It’s best described as a Linux computer running on a mobile phone processor that is the emotional descendant of the classic BBC Micro. It emerged from an educational computing project to produce a small, very cheap Linux computer for the education market, suitable for tinkering with electronics and robotics, and to provide young programmers with the kind of open-ended computing experience that its founders remembered from the 1980s and believed was missing in the world of games consoles.
Over the years it has appeared in several form factors, including an absolutely tiny, keyfob-sized computer that was given away as a freebie stuck to the front cover of a magazine!
The most recent product — today’s brand new Raspberry Pi 400 — is perhaps the most loudly reminiscent of those 1980s computers. It’s a very powerful little computer, hidden in a neat little keyboard, for less than £100, that can plug into a modern television.
Despite their low cost, these aren’t particularly underpowered computers — within certain limits. The Raspberry Pi 4 is a 64 bit machine equipped with an ARM processor and up to 8GB of RAM.
So, can it run Smartform?
Yes!
We have experimented with the Raspberry Pi 2 and Pi 3 over the years and found those machines rather less satisfactory for giant databases. Of course, since it’s a petite Linux machine, the MySQL and shell-scripts approach of our Linux product has always worked, if you’ve been prepared to put up with a lot of fiddling and a not particularly quick response.
In 2020, we think the Pi 4 is fast and capable enough that we’re offering some early support for it.
Is it actually fast?
Ye–eees.
The 8GB ram Pi 4 is broadly comparable in CPU performance terms to Amazon’s a1.large EC2 instance. No slouch.
There’s a big caveat here, though. As a tiny little computer sold for a tiny little price, the storage is tiny little memory cards: Micro SD. The kind you use in mobile phones.
SD and Micro SD cards are very fast for reading in a sequential fashion — no problem for a HD movie — but they are very slow for random-access reads and writes, so loading a database with huge number of INSERT statements isn’t fast.
But once your database is loaded, SD read speeds with good modern cards (we’ve had good results with SanDisk Ultra micro SD) are not so bad for tinkering. Just not fast enough to use as your main analytics tool.
For much faster disk performance, the Pi 4 and Pi 400 are the first machines to offer USB3, so external disks can be quick — and while the Pi normally boots from the MicroSD card, you can set them up to boot from a USB 3 drive.
We have had good results with a UASP caddy with an SSD drive inside. Here’s a great video from Jeff Geerling to explain:
At this point, you could have an 8GB RAM, 64-bit, SSD-equipped computer for not much more than £100 that can be set up to run quietly in a corner and do your Smartform tasks for you on a schedule.
Then you can connect to it over WiFi from your database tools, or plug a monitor, keyboard and mouse in and use it as a dedicated mini desktop.
What is different to an ordinary Linux PC?
Not all that much, actually, aside from the SD card aspect. And the price.
The key difference is that the Raspberry Pi has an ARM processor (which is why it is cheap), instead of an Intel processor.
So you might be compiling a few things yourself, perhaps, and we have our own Raspberry Pi builds of our new Smartform updater.
Why use this rather than a PC?
Apart from having to share disk space with the family’s FPS game collection? We like the idea of Smartform as an appliance, of course; Smartform in a tiny box.
More generally we think an interesting thing about the Pi 4 is the possibility to inexpensively dedicate a machine to a single task such as machine learning (the Pi 4 has a GPU).
Also the potential to use more than one of them in a small cluster. The Pi 4 supports gigabit ethernet, so it is not too tricky to imagine adding more computing power by distributing tasks over multiple machines.
So how do I get started?
You can set up your Raspberry Pi either by following the instructions that come with your Pi, or on their website.
Installing Smartform is mostly the same as installing it for Linux, except for the different updater binary. You can get the updater binary and read a little bit more here.
What does the future hold for Smartform on the Pi?
I think we’re not sure yet.
For my own perspective, I’m looking forward to a time when a Pi 4 installation is my reference implementation for the loader and the code.
Also I am particularly interested in the possibility of making an installer that can configure a turnkey appliance Smartform setup on a Pi without any user interaction at all; we know it can be a little fiddly to get Smartform going, so it would be great to have this sort of tool.
That appliance setup could be used as the basis of an off-the-shelf betting robot or machine learning project.
(Plus, using the new historic_runners_insights table in Smartform you can implement simple systems in pure SQL, no need to delve into machine learning unless you want to — Colin)
What would you want to try?
Looking at the importance of variables.
By Steve Tilley on Sunday, August 23rd, 2020This article shows how you can compare how important different variables are from the historical insights table in Smartform.
The article provides a skeleton where you can test other variables for other types of races. I have put the whole R code at the end of article
In the Historical Insights table are some new variables. I am going to look at a group of these.
- won_LTO, won_PTO, won_ATO, placed_LTO, placed_PTO, placed_ATO, handicap_LTO. handicap_PTO, handicap_ATO, percent_beaten_LTO, percent_beaten_PTO and percent_beaten_ATO
These are quite self-explanatory with LTO meaning last time out, PTO is penultimate time out and ATO, antepenultimate time out or three runs ago.
I have chosen to look at all UK all-weather handicaps since January 1st 2017. I have chosen handicaps as the runners will generally have several previous runs. I have guaranteed this by only selecting horses that have more than three previous runs.
I will be using a package called Boruta to compare the variables so you will need to install that if you do not already have it.
library("RMySQL")
library("dplyr")
library("reshape2")
library("ggplot2")
library("Boruta")As always I do a summary of the data. Here I need to deal with NA values, and there are some in the historic_runners.finishing_position field. Because I have over 55000 rows of data and only 250 NAs I have deleted those rows.
smartform_results <- na.omit(smartform_results)I need to add a variable to tell me if the horse has won the race or not, I have called this winner. It will act as a target for my other variables.
smartform_results$Winner = ifelse(smartform_results$finish_position < 2,1,0)Then I need to select the variables I wish to compare in their importance in predicting the winner variable.
allnames=names(smartform_results)
allnames
[1] "course" "meeting_date" "race_id" "race_type_id" "race_type"
[6] "distance_yards" "name" "finish_position" "starting_price_decimal" "won_LTO"
[11] "won_PTO" "won_ATO" "placed_LTO" "placed_PTO" "placed_ATO"
[16] "handicap_LTO" "handicap_PTO" "handicap_ATO" "percent_beaten_LTO" "percent_beaten_PTO"
[21] "percent_beaten_ATO" "prev_runs" "Winner" This gives me a list of all the variables in my data.
I must admit when downloading data from a database I like to include a variety of race and horse variables to make sure my selection criteria have worked properly. For example race and horse names. I now need to remove these to make a list of the variables I need.
I can see I have 23 variables, and from the output of allnames I can work out which ones I don’t need and get their numerical indices. I find it easier to work with numbers than variable names at this stage. Notice I’ve removed my target variable, winner.
datalist=allnames[-c(1,2,3,4,5,6,7,8,9,22,23)]
> datalist
[1] "won_LTO" "won_PTO" "won_ATO" "placed_LTO" "placed_PTO" "placed_ATO"
[7] "handicap_LTO" "handicap_PTO" "handicap_ATO" "percent_beaten_LTO" "percent_beaten_PTO" "percent_beaten_ATO"
> target=allnames[23]
> target
[1] "Winner"So datalist contains all the variables I am testing and target is the target that they are trying to predict.
I use these to produce the formula that R uses for most machine learning and statistical modelling
mlformula <- as.formula(paste(target,paste(datalist,collapse=" + "), sep=" ~ "))All this rather unpleasant looking snippet does is produce this formula.
Winner ~ won_LTO + won_PTO + won_ATO + placed_LTO + placed_PTO +
placed_ATO + handicap_LTO + handicap_PTO + handicap_ATO +
percent_beaten_LTO + percent_beaten_PTO + percent_beaten_ATO
This means predict the value of Winner using all the variables after the ~ symbol.
This translates as, predict winner using all the variables named after the ~ symbol.
At last, we can use Boruta to see which of our variables is the most important. I am not going to give a tutorial in using Boruta. There are numerous ones available on the internet. There are various options you can use. I have just run the simple vanilla options here. It will take a little while to run depending on the speed of your machine
Once it has finished, you can do one more thing. This line forces Boruta to decide if variables are important.
final.boruta <- TentativeRoughFix(boruta.train)Here is the output. Do not worry if your numbers do not exactly match they should be similar.
meanImp medianImp minImp maxImp normHits decision
won_LTO 17.454272 17.336936 15.2723929 19.681327 1.0000000 Confirmed
won_PTO 11.858611 11.847156 9.6080635 13.915011 1.0000000 Confirmed
won_ATO 10.646576 10.571548 8.5119054 12.529334 1.0000000 Confirmed
placed_LTO 22.967911 23.035708 20.2490144 25.244789 1.0000000 Confirmed
placed_PTO 21.871156 21.946160 19.2961340 24.466836 1.0000000 Confirmed
placed_ATO 20.242410 20.231261 17.3522156 22.853500 1.0000000 Confirmed
handicap_LTO 2.437791 2.360027 -0.9938698 5.342918 0.4747475 Confirmed
handicap_PTO 7.568926 7.620271 4.2983632 11.147914 1.0000000 Confirmed
handicap_ATO 9.521332 9.551424 5.7088247 13.628699 1.0000000 Confirmed
percent_beaten_LTO 34.039496 34.076843 30.2324486 38.099816 1.0000000 Confirmed
percent_beaten_PTO 27.804420 27.716601 24.2223531 31.686299 1.0000000 Confirmed
percent_beaten_ATO 22.990647 23.121783 19.8763102 25.945583 1.0000000 ConfirmedAll the variables are confirmed as being important related to the target variable. The higher the value in the first column the more important the variable. Here the percent beaten variables seem to do well while the handicap last time out is only just significant.
You can see this better in a graph.
plot(boruta.train, xlab = "", xaxt = "n")
lz<-lapply(1:ncol(boruta.train$ImpHistory),function(i) boruta.train$ImpHistory[is.finite(boruta.train$ImpHistory[,i]),i])
names(lz) <- colnames(boruta.train$ImpHistory)
Labels <- sort(sapply(lz,median))
axis(side = 1,las=2,labels = names(Labels), at = 1:ncol(boruta.train$ImpHistory), cex.axis = 0.7)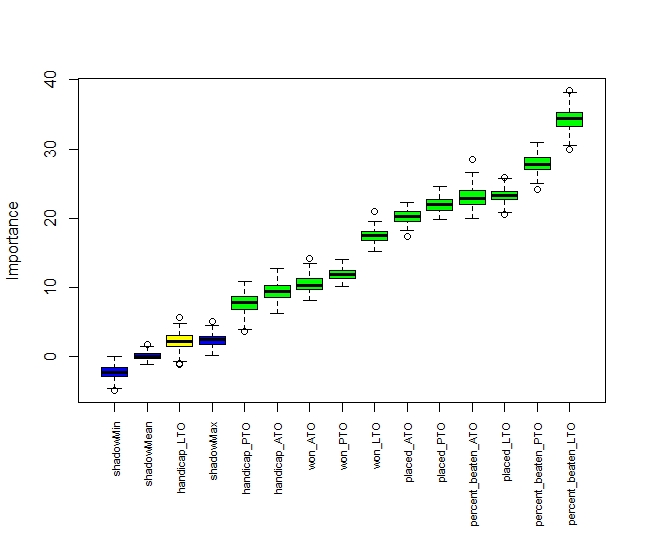
Handicap LTO is yellow as that is only just significant. The rest are green and are significant. The three blue variables are what we might expect by chance, read up more on Boruta for more details..
It is also worth noting for each variable apart from handicap LTO the most recent race is the most significant. SO LTO is more significant than PTO which is more significant than LTO.
By looking at variable importance, we can concentrate our modelling on those that are most important to our outcome
The importance of variables will vary with the type of race you are studying. What is important to all-weather handicaps may well not be important in long-distance Novice Chases.
Hopefully, you can use the attached script as a blueprint for your particular analyses.
library("RMySQL")
library("dplyr")
library("reshape2")
library("ggplot2")
library("Boruta")
con <- dbConnect(MySQL(),
host='127.0.0.1',
user='smartform',
password='*************',
dbname='smartform')
sql1 <- paste("SELECT historic_races.course,
historic_races.meeting_date,
historic_races.race_id,
historic_races.race_type_id,
historic_races.race_type,
historic_races.distance_yards,
historic_runners.name,
historic_runners.finish_position,
historic_runners.starting_price_decimal,
historic_runners_insights.won_LTO,
historic_runners_insights.won_PTO,
historic_runners_insights.won_ATO,
historic_runners_insights.placed_LTO,
historic_runners_insights.placed_PTO,
historic_runners_insights.placed_ATO,
historic_runners_insights.handicap_LTO,
historic_runners_insights.handicap_PTO,
historic_runners_insights.handicap_ATO,
historic_runners_insights.percent_beaten_LTO,
historic_runners_insights.percent_beaten_PTO,
historic_runners_insights.percent_beaten_ATO,
historic_runners_insights.prev_runs
FROM smartform.historic_runners
JOIN smartform.historic_races USING (race_id)
JOIN smartform.historic_runners_insights USING (race_id, runner_id)
WHERE historic_races.meeting_date >= '2019-01-01' AND historic_races.race_type_id=15 AND historic_runners_insights.prev_runs>3 AND historic_races.course!='Dundalk'AND historic_races.handicap=1", sep="")
smartform_results <- dbGetQuery(con, sql1)
View(smartform_results)
dbDisconnect(con)
smartform_results <- na.omit(smartform_results)
smartform_results$Winner = ifelse(smartform_results$finish_position < 2,1,0)
allnames=names(smartform_results)
allnames
datalist=allnames[-c(1,2,3,4,5,6,7,8,9,22,23)]
datalist
target=allnames[23]
target
mlformula <- as.formula(paste(target, paste(datalist,collapse=" + "), sep=" ~ "))
mlformula
print(mlformula)
set.seed(123)
boruta.train <- Boruta(mlformula, data =smartform_results, doTrace = 2)
print(boruta.train)
final.boruta <- TentativeRoughFix(boruta.train)
boruta.df <- attStats(final.boruta)
print(boruta.df)
plot(boruta.train, xlab = "", xaxt = "n")
lz<-lapply(1:ncol(boruta.train$ImpHistory),function(i) boruta.train$ImpHistory[is.finite(boruta.train$ImpHistory[,i]),i])
names(lz) <- colnames(boruta.train$ImpHistory)
Labels <- sort(sapply(lz,median))
axis(side = 1,las=2,labels = names(Labels), at = 1:ncol(boruta.train$ImpHistory), cex.axis = 0.7)Tongue tie on the 1000 Guineas favourite – should we be worried?
By colin on Sunday, June 7th, 2020Reviewing the 1000 Guineas today, I could not help but be drawn to the favourite, Quadrilateral, unbeaten daughter of Frankel, arguably the most impressive winner of the 2,000 Guineas, ever.
3/1 is on offer, a short enough price. But if she is anywhere near as good as Frankel, that’s a long price indeed!
But what is this in the declarations? First time tongue strap.
Should we be worried?
A little bit (ok quite a lot) of data manipulation in Smartform enables us to build a table of runner records with counts of when a tongue strap was applied, such that we can group records into all, tongue strap and first time tongue strap. A further grouping of these records by trainer reveals the following records for Roger Charlton, Quadrilateral’s own handler:

You’ll have to click on the image to see this properly, it’s a table View straight out of R, but long story short, rounding those figures to the nearest whole number, here’s the picture for Roger Charlton:
- 17% overall win strike
- 12% win strike when applying tongue strap
- 9% win strike when applying first time tongue strap
So the answer to the question “Should we be worried?” has to be “Yes” (unless my rapid calculations have gone awry somewhere!). Does this mean the favourite can’t win? Of course not. But can’t be betting at such short odds, personally, with such doubts and no real explanation at hand.
The only references I can find from the trainer are his bullish sounding quote in today’s Post:
“We’re looking forward to it. She looks magnificent. She’s a big, strong filly and these are exciting times. I hope she can run as well as she did the last time she went to Newmarket.”
And the rather anodyne message from the trainer’s own blog:
“The fourth runner to head out is Quadrilateral at Newmarket in the ‘Qipco 1000 Guineas Stakes’ for her owner Prince Khalid Abdullah. The daughter of Frankel had three runs as a two year old last season in which she maintained an unbeaten record throughout. It included the Group 1 ‘bet365 Fillies Mile’ at Newmarket which landed her with an official rating of 114. The race holds 15 competitive runners as to be expected and we have a draw of 6. Jason Watson takes the ride. She has wintered very well and remains a filly with an impressive physique, who holds her condition well. There is a little bit more rain expected between now and the race which won’t bother her and we are excited to get her on the track.”
Nothing about the reasoning behind the statistically negative tongue tie, which I suppose is to be expected in the run up to a big race with so much at stake.
Fingers crossed she runs well, but will have to take a watching brief, and will be looking elsewhere for some each way value.