
The Epsom Classics Through Two Lenses: How Far Can Pedigree Statistics Take You?
By colin on Friday, June 5th, 2026Yesterday’s dam-table release completed Smartform’s pedigree picture. So we built two models of the Epsom Classics — one using everything, one using breeding alone — and asked how much of the picture pedigree can paint on its own.
With yesterday’s release of daily_dams_insights, the Smartform pedigree canon is now three deep: daily_sires_insights, the new daily_dams_insights, and the sire × damsire cross, which only exists because the native database carries damsire references for every horse. Thus a complete picture, paternal and maternal, is queryable for every UK and Irish runner since 2008: the production form of a runner’s sire, dam, damsire and breeding cross, across aggregate, recent, age-, distance-, course- and condition-specific lenses, in both PRB and strike rate.
The Epsom Classics are the natural place to test it. The Oaks and Derby are the deepest mid-distance Classic trials in the calendar — top-of-pyramid three-year-old Group 1s over twelve furlongs, where any stamina and Classic-distance signal in the breeding should be doing its hardest work — and they come with a tightly bounded sample (18 useful runnings since our pedigree data starts in 2008), which makes it tractable to ask exactly which signals move the needle.
So we ran a two-model experiment. A full model uses everything we hold — pedigree plus jockey, trainer and the runner’s own prior form. A parallel pedigree-only model sets the form and connections aside and keeps only the pedigree features: sire, dam, damsire and the breeding cross. The question: how much of the full model’s predictive power survives that restriction?
The short answer is most of it — and on the Oaks, all of it. The pedigree-only model is a genuine second opinion in its own right, not a stripped-down copy of the full one. And whether the two models agree or disagree turns out to be more useful than either on its own.
Why a composite, not a black box
Eighteen runnings is no place for a hundred-feature gradient booster; throw that much at this little data and you model noise. We needed something simpler and more honest. For every candidate stat — 138 in all, every variant across sire, dam, damsire and the breeding cross, plus jockey, trainer and self prior form for the full model — we take its Spearman rank correlation with finishing position across the cohort. The strongest discriminators become the features; each one’s weight is its signed Spearman value. A runner’s score is its z-score on each weighted stat, summed and softmaxed within the race.
To check it generalises, we ran leave-one-year-out across 2008–2025: hold out each year, refit the weights on the other seventeen, score the held-out race. That gives eighteen genuinely out-of-sample predictions per Classic, per model.
What the data picks — and what it ignores
We let the data choose from the whole arsenal. What rose to the top was sire and dam. The damsire and the breeding cross, on this sample, didn’t reach the top tier of discriminators at all — which is itself worth knowing: at the very top of the mid-distance pyramid, it is the direct sire and dam lines that carry the signal. Having the full picture is precisely what let us find that out.
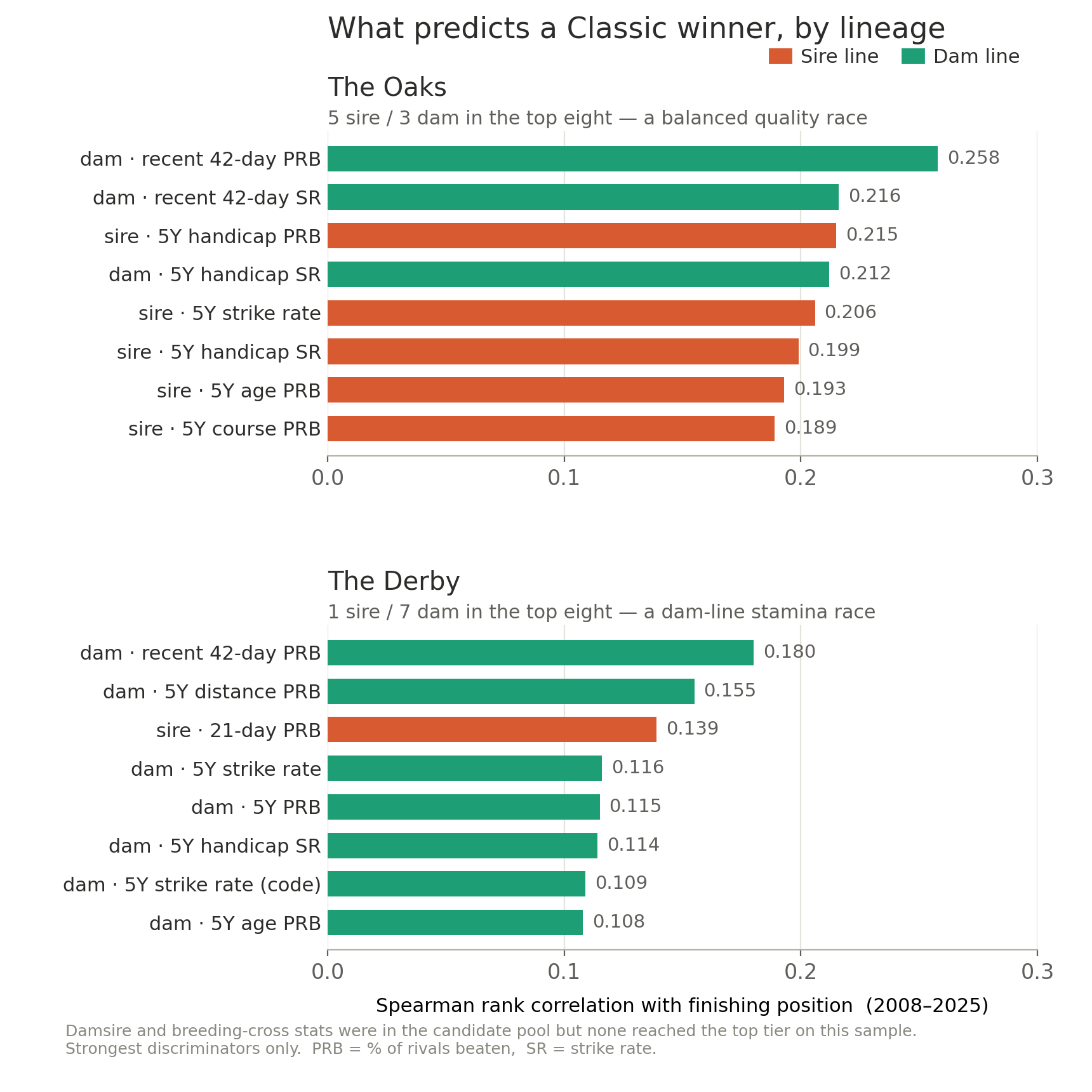
Top breeding discriminators for each Classic, coloured by lineage. The Oaks profile is balanced; the Derby’s is almost entirely dam-led.
Two patterns fall out. The Oaks is balanced — five sire stats and three dam stats in the top eight, the dam contributing recency (42-day progeny form) and the sire contributing five-year quality (strike rate, age- and condition-PRB). It reads as a quality race. The Derby is overwhelmingly dam-led — seven of the top eight are dam stats, with the dam’s five-year progeny PRB at twelve-furlong distances the second-strongest of all the Derby signals; the sire appears only through its last-three-weeks form, not any aggregate. It reads as a stamina race.
One honest caveat sits behind both profiles. The strongest single discriminator in each race is the dam’s 42-day progeny PRB — and for a dam with only a handful of foals, the progeny runs inside a 42-day window are usually little more than the runner’s own last one or two starts. So while the model carries no explicit form, jockey or trainer features, its top signal is in practice a proxy for the horse’s own recent form, arriving through the dam column rather than a form one.
A second caution, on sample size: among the Derby signals, one shows a positive rank correlation but a negative top-versus-bottom-quartile lift. These are eighteen-race rankings, not laws of nature.
How both models held up over 18 years
| Top-1 hits | Top-3 hits | Mean winner rank | |
|---|---|---|---|
| Oaks — full | 3 / 18 (17%) | 9 / 18 (50%) | 4.4 |
| Oaks — pedigree | 3 / 18 (17%) | 9 / 18 (50%) | 5.0 |
| Derby — full | 2 / 18 (11%) | 7 / 18 (39%) | 5.9 |
| Derby — pedigree | 2 / 18 (11%) | 5 / 18 (28%) | 6.7 |
On the Oaks the pedigree-only model matches the full one outright — same 50% top-3 rate, same 17% of winners found outright. That parity isn’t quite magic: its two strongest Oaks features are both 42-day dam stats, recent self-form in disguise, so it is quietly leaning on the same recent-form signal the full model uses openly. On the Derby it gives up ground (top-3 falls from 39% to 28%) but still finds the winner outright in 2 of 18 renewals — and here the work is done by genuine aggregate dam stamina, not the recency proxy. That’s a strong showing for a model that deliberately sets aside the form and connections factors that do most of the full model’s work, and leans on breeding alone.
More interesting is where the two models agree on the winner:
| Verdict | Count |
|---|---|
| Both models had the winner in their top-3 | 8 / 36 (22%) |
| Only the full model did | 8 / 36 (22%) |
| Only the pedigree model did | 6 / 36 (17%) |
| Neither | 14 / 36 (39%) |
At least one model lands the winner inside its top-3 in 22 of 36 Classics — 61%. Read that with care: a combined six-horse shortlist is a sizeable slice of a Classic field, so the fair comparison is against the market’s own shortlist rather than treating 61% as a standalone edge. The genuinely useful point is that the two books rarely both miss, and that the split between them is informative.
That split is the structural takeaway. On the Oaks the two models agree on the winner in 7 of 18 years (39%) — Snowfall (2021), Anapurna (2019) and Minding (2016) among them, all heavily fancied Coolmore winners with clean pedigree credentials and good form. When both books light up the same Oaks runner, you have a high-confidence pick. On the Derby they agree only once in 18 years (Ruler of the World, 2013). The Derby winner is almost always found by one model and missed by the other: Pour Moi (2011) caught by pedigree alone and missed by the full model; Auguste Rodin (2023) the reverse. That asymmetry is the argument for running both books in parallel rather than averaging them — they draw on genuinely different signal, and which one dominates depends on the race.
The 2026 read
With the weights refit on the full 2008–2025 set (for live scoring there is nothing left to hold out), here is how this year’s declarations score. These are model outputs, not tips — and as the section below makes clear, the models don’t see everything.
Oaks (Friday). Pedigree top three: A La Prochaine, Legacy Link, Sugar Island. Full top three: Amelia Earhart, Legacy Link, A La Prochaine. Both books share Legacy Link (the market favourite) and A La Prochaine (the value-tilted version of the same signal) — the high-confidence Oaks shape. Amelia Earhart is the full model’s standalone pick, on form and connections that pedigree alone can’t see; Sugar Island is the pedigree model’s standalone pick, on Coolmore breeding the form view under-weights.
Derby (Saturday). Pedigree top three: Item, Maltese Cross, Christmas Day. Full top three: Benvenuto Cellini, Item, Maltese Cross. Item is the only horse in both books’ top three — the rare Derby-agreement shape that has appeared just once in eighteen holdout years. Benvenuto Cellini is the full model’s standalone pick; Christmas Day is the pedigree model’s, and the biggest market overlay of the lot.
Each of those standalone shapes has produced Classic winners before — and missed plenty too. The honest guide to how often is the hit-rate table above, not the handful of names that happened to win.
What we wouldn’t do. Both models rate Pierre Bonnard and Ancient Egypt as Derby outsiders, and since pedigree alone dislikes them too, it isn’t a form-versus-breeding artefact. But the market knows things our entity-stat snapshots — taken 24 to 48 hours out — don’t: going, late money, stable information. We’ve flagged the disagreement; we wouldn’t oppose them on it.
What it tells us about the data
The finding isn’t that pedigree alone is as good as pedigree plus form — on the Derby it gives up about ten points of top-3 hit rate. It’s that it gives up far less than you’d expect from a model that sets aside the form and connections data entirely, and on the Oaks it gives up nothing at all. That makes pedigree-only modelling a viable second opinion on the Classics, not a poor relation of the form-based view — and it’s the new dam table that completes the picture and gives that view its backbone. When the two books agree, you have a high-confidence pick; when they split, the split itself tells you whether the case is breeding-led or form-led.
Our own reading leans on the breeding — it is, after all, what the new dam table now lets us see most clearly. In the Oaks that points to A La Prochaine, with Sugar Island the pure-breeding flyer; in the Derby, to Item ahead of Christmas Day, the biggest breeding-led overlay or value pick on the card. And it isn’t at odds with the full model where it counts: both books land A La Prochaine and Legacy Link in the Oaks, and both land Item in the Derby — the overlaps where confidence is highest.
— Betwise / Smartform